Excel-кластеризатор главных слов по; весу
главных слов по весу
Вручную группировать запросы не постоянно отлично: перебрать запросов можно за час, уйдет неделька. Автоматическим сервисам группировку я не доверю, потому что она описывает структуру и маневренность кампании.
Потому вымыслил собственный способ, который ускоряет кластеризацию и даёт осознанный итог. Упрощает жизнь при работе главных слов. Пробовал работать с 45 000 — Excel начинал дохнуть. Перечень запросов резвее перебрать руками.
Дальше расскажу про собственный способ кластеризации в теории, а потом — как реализую его в Excel. Дам ссылку на готовый . Но чтоб им воспользоваться, необходимо отлично осознавать способ.
Способ
Кластеризация — распределение запросов по кластерам. Кластер — это группа запросов, похожих по смыслу и набору слов. Чтоб выделить такие запросы и соединить их в кластер, нужен признак.
Используем для этого нормализованную форму запроса — уберём окончания и выстроим слова в порядке значимости:

Удаление окончаний дозволит охватить все вероятные словоформы для определенного слова, а сортировка «по значимости» — игнорировать порядок слов.
Убираем окончания
Слово без окончания — это признак, который соединяет воединыжды различные словоформы:
Чтоб убирать окончания я использую mystem. Это лемматизатор от Yandex’а. Он обрабатывает перечень слов и возвращает нормализованные значения — леммы.
Если система не уверена, какая лемма верная, то покажет . К примеру, для слова «банку» mystem вернёт две леммы: «банк» и «банка». При проверке результатов мы выберем подходящую.
Определяем значимость
Сортировка «по значимости» дозволит игнорировать порядок слов. При сортировке нормализованных значений фраз по алфавиту мы получим готовые кластеры — группы запросов, похожих по смыслу и набору слов.
Значимость слова — вычисляемый параметр для определенного перечня главных слов. Он не описывает значимость слова в общей картине мира.
Значимость слова рассчитывается из частотности и количества упоминаний слов в перечне. Разглядим на примере.
Берём перечень запросов с частотностью
- Приобрести бумеранг — 1000
- Бумеранги стоимость — 700
- Бумеранги в москве — 750
- Приобрести традиционный бумеранг — 450
- Цены на бумеранги в москве — 350
- Приобрести традиционный бумеранг в москве — 100
В перечне запросов встречаются слова: приобрести, бумеранг, традиционный, москва, стоимость, в, на. Вес слова равен сумме толикой частотностей помноженных на количество упоминаний слова.
Считаем толики частотностей
- Приобрести бумеранг — 1000 = 1000/2 = 500
- Бумеранги стоимость — 700 = 700/2 = 350
- Бумеранги в москве — 750 = 750/3 = 250
- Приобрести традиционный бумеранг — 450 = 450/3 = 150
- Цены на бумеранги в москве — 350 = 350/5 = 70
- Приобрести традиционный бумеранг в москве — 100 = 100/5 = 20
Считаем вес слов
- Приобрести — (500+150+20)*3 = 2010
- Бумеранг — (500+350+250+150+70+20)*6 = 8040
- Традиционный — (150+20)*2 = 340
- Москва — (250+70)*2 = 640
- Стоимость — (350+70)*2 = 840
- В — 20
- На — 70
Сортируем по значимости
- 8040 — бумеранг
- 2010 — приобрести
- 840 — стоимость
- 640 — москва
- 340 — традиционный
- 70 — на
- 20 — в
Располагаем запросы по значимости
- Приобрести бумеранг — бумеранг | приобрести
- Бумеранги стоимость — бумеранг | стоимость
- Бумеранги в москве — бумеранг | москва
- Приобрести традиционный бумеранг — бумеранг | приобрести | традиционный
- Цены на бумеранги в москве — бумеранг | стоимость | москва | на | в
- Приобрести традиционный бумеранг в москве — бумеранг | приобрести | москва | традиционный | в
Упорядочиваем и чистим
- Бумеранг | приобрести: приобрести бумеранг — 1000
- Бумеранг | приобрести | традиционный: приобрести традиционный бумеранг — 450
- Бумеранг | приобрести | москва | традиционный: приобрести традиционный бумеранг в москве — 100
- Бумеранг | москва: бумеранги в москве — 750
- Бумеранг | стоимость: бумеранги стоимость — 700
- Бумеранг | стоимость | москва: цены на бумеранги в москве — 350
В итоге получили 1-ые группы объявлений, с которыми можно работать далее: укрупнять, соединять воединыжды, . Для этого используем Excel.
Реализация в Excel
Исполняем последовательность действий в таблице (XLS, 537 КБ) с формулами. Кластеризация 1000 запросов займет 30 минут.
Метод одной строчкой
Собираем СЯ → собираем частотность → разбиваем запросы по словам и вычисляем толики весов → формируем с весами слов → выделяем леммы для слов → вычисляем «вес» леммы → формируем с леммами → делаем первичную кластеризацию → укрупняем приобретенные группы.
Шаг 1. Вычисляем толики весов и разбиваем запросы по словам
Лист «Кластеризация», таблица «Main»
Чтоб избежать правки формул именуйте все листы и таблицы аналогично
- Вычисляем толики весов:
- Толики весов = Частотность / .
- =LEN ([@Ключ])-LEN (SUBSTITUTE ([@Ключ],» «,»»))+1.
Шаг 2. Формируем с весами слов
Лист «Слова — Леммы», таблица «Word»
- Копируем столбцы W1—W7 на новейший лист.
- Преобразуем таблицу из формата
[W1] [W2] [W3] [W4] [W5] [W6] [W7] [Доли весов] в формат:
[W1] → [Доли весов]
[W2] → [Доли весов]
[W3] → [Доли весов]
[W4] → [Доли весов]
[W5] → [Доли весов]
[W6] → [Доли весов]
[W7] → [Доли весов]:
Шаг 3. Выделяем леммы и дорабатываем справочник со словами
Лист «Слова — Леммы», таблица «Word»
- Копируем приобретенный на прошедшем шаге перечень слов «как есть».
- Обрабатываем через mystem → получаем леммы для всякого слова.
- Считаем каждой леммы.

Шаг 4. Формируем с леммами
Лист «Леммы», таблица «Lemmas»
- Копируем приобретенный перечень лемм на новейший лист и удаляем дубли.
- Из справочника со словами подтягиваем -во упоминаний каждой леммы.
- Считаем в лемме.
- Вычисляем «вес» леммы:
Вес Леммы= [Сумма долей весов слов, входящих в Лемму] * [ Леммы].
Формула:
=(SUMIF (Words[Lemma],[@Лемма], Words[Доли весов]))*[@[]]. - Сортируем леммы по столбцу «вес» — от большего к наименьшему.
- Проставляем «Статус» для лемм — малый для старшей леммы (лучше начать с 1 000), далее +1 к последующему статусу:
Шаг 5. Делаем первичную кластеризацию
Лист «Кластеризация», таблица «Main»
Для всякого слова в столбцах W1—W7 подтягиваем «Статус» → записываем их столбцы :
Итак, что мы сделали. Разбили запросы по словам. Для всякого слова выделили лемму — можем соединить запросы по общим словам. Для каждой леммы посчитали вес. Остаётся выстроить слова в запросе в порядке значимости. Тогда при сортировке по алфавиту запросы сами сольются в группы объявлений.
Выстраиваем слова в порядке значимости функцией SMALL. В спектре статусов L1 – L7 отыскиваем самый небольшой статус — это самое принципиальное слово во фразе. Потом, отыскиваем 2-ой самый небольшой статус — это 2-ое по значимости слово во фразе. И так еще 5 раз — проверяем оставшиеся столбцы L3 – L7.
Получаем последовательность статусов. К примеру, 37 → 100 → 200 → 700. Для всякого статуса подтягиваем Лемму из справочника Лемм. Соединяем Леммы нормализованное значение фразы. Я использую его как заглавие группы объявлений.
Сортируем по алфавиту:
Полная рабочая формула .
Шаг 6. Укрупняем приобретенные группы
Игнорируя окончания и порядок слов, мы соединили запросы с схожим набором слов. Количество групп стремится к количеству слов — это 100 % точность инструмента. Можно применять, если вы предпочитаете работать с запросами в четком согласовании.
Чтоб укрупнить группы, необходимо уменьшить точность — понизить количество лемм, которые составляют «нормализованную форму».
Что можно удалить:
- одинокие буковкы, числа, предлоги, доменные зоны. Леммы длиной ;
- редчайшие леммы — меньше среднего по списку;
- леммы с малым весом — недостаточно «принципиальные»;
- в редчайших вариантах — топонимы.
Принципиально: лемму не удаляем, лишь её «Статус» — этого довольно, чтоб лемма не попала в «нормализованную форму»:
В главный таблице ничего править не нужно — итог обновится без помощи других.
До какой степени укрупнять: я стремлюсь к среднему показателю в одной группе объявлений и смотрю за наибольшим количеством фраз (помним про ограничения систем контекстной рекламы).
Резюме
Приобретенный перечень групп комфортно и двигать меж кампаниями. Заглавие группы поможет писать объявления — вы сами определяете принципиальные слова в заглавии группы.
Ещё раз метод: собираем СЯ → собираем частотность → разбиваем запросы по словам и вычисляем толики весов → формируем с весами слов → выделяем леммы для слов → вычисляем «вес» леммы → формируем с леммами → делаем первичную кластеризацию → укрупняем приобретенные группы.
Отзывы джедаев о кластеризаторе
«Я помогал Роме с созданием инструмента на ранешних шагах. Всем рекомендую испытать кластеризатор для ядра от 2000 главных слов → сбережет время.
Инструмент можно сделать лучше и перевоплотить в автоматический сервис. Также можно дорабатывать формулы определения веса лемм. Да и в текущем виде он поможет спецам по контексту, которые работают с большенный семантикой.»
«При помощи кластеризатора очень удобнее и резвее сгруппировать фразы и позже писать объявления для их. Из недочетов — 1-ый раз кажется, что это сложно. Но когда попробуешь, то всё достаточно понятно. Но эту штуку лучше заавтоматизировать.»
«Методику пробовал, но не использую в работе, поэтому что нечасто собираю контекст в огромных размерах.
Отлично подойдет для работы с большенный семантикой, в особенности в свете крайних инноваций yandex’а по низкочастотным запросам. Группировки посодействуют сберечь много времени при подготовке главных фраз.
Методика на 1-ый взор кажется сложной и массивной, но если разобраться, то процесс становится понятным и комфортным.»
«Кластеризация от Ромы просто находка! Способом пользуюсь всякий раз когда работаю с семантикой — собираю либо изменяю кампании.
Больше всего мне нравятся три вещи:
- я регулирую какие фразы попадут в группу. Если вес фразы маленький, то объединяю с схожими. Не придерживаюсь принципа «один ключ — одна группа», по другому управлять кампанией трудно;
- понимаю механику и вижу какие фразы должны быть в заголовке. Естественно, принципиально созодать полное вхождение главного слова. Нередко оно не вмещается на сто процентов и я строю заголовок из фраз с бо́льшим весом;
- это Excel, который всем знаком. Не надо устанавливать доп программки и платить за сервис. Если разобраться в формулах, то уже незначительно прокачаешься.
Из минусов: все формулы я копирую из готового шаблона и переключаться меж окнами одной программки неловко. Я бы желала иметь формулы под рукою, а в состоянии сделать в дальнейшем шаблон, чтоб уменьшить количество копирований. Ещё хотелось бы уменьшить время группировки, но пока не отыскала метод.
В целом, метод мне нравится тем, что механика обычная и понятная, её просто ввести и позже управлять кампаниями.»
Что далее
Если у вас главных слов, используйте этот метод. Прогоните метод , чтоб «впитать».
Если у вас перечень запросов, переберите руками — так резвее.
Если желаете готовое решение — попросите программистов написать скрипт.
Я повсевременно дорабатываю кластеризатор. В последующих итерациях желаю проработать групп, добавить справочники и очень заавтоматизировать кластеризатор на Power Query. Смотрите за обновлениями!
How to run cluster analysis in Excel
This is a step by step guide on how to run k-means cluster analysis on an Excel spreadsheet from start to finish. Please note that there is an Excel template that automatically runs cluster analysis available for free download on this website. But if you want to know how to run a k-means clustering on Excel yourself, then this article is for you.
In addition to this article, I also have a video walk-through of how to run cluster analysis in Excel.
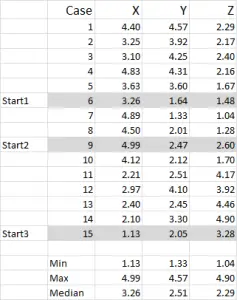
Step One – Start with your data set
Figure 1
For this example I am using 15 cases (or respondents), where we have the data for three variables – generically labeled X, Y and Z.
You should notice that the data is scaled 1-5 in this example. Your data can be in any form except for a nominal data scale (please see article of what data to use).
NOTE: I prefer to use scaled data – but it is not mandatory. The reason for this is to “contain” any outliers. Say, for example, I am using income data (a demographic measure) – most of the data might be around $40,000 to $100,000, but I have one person with an income of $5m. It’s just easier for me to classify that person in the “over $250,000” income bracket and scale income 1-9 – but that’s up to you depending upon the data you are working with.
You can see from this example set that three start positions have been highlighted – we will discuss those in Step Three below.
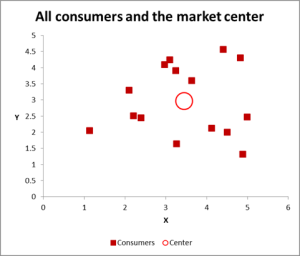
Step Two – If just two variables, use a scatter graph on Excel
Figure 2
In this cluster analysis example we are using three variables – but if you have just two variables to cluster, then a scatter chart is an excellent way to start. And, at times, you can cluster the data via visual means.
As you can see in this scatter graph, each individual case (what I’m calling a consumer for this example) has been mapped, along with the average (mean) for all cases (the red circle).
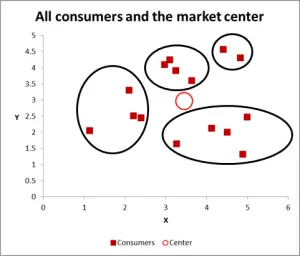
Depending upon how you view the data/graph – there appears to be a number of clusters. In this case, you could identify three or four relatively distinct clusters – as shown in this next chart. Figure 3
With this next graph, I have visibly identified probable cluster and circled them. As I have suggested, a good approach when there are only two variables to consider – but is this case we have three variables (and you could have more), so this visual approach will only work for basic data sets – so now let’s look at how to do the Excel calculation for k-means clustering.
Step Three – Calculate the distance from each data point to the center of a cluster
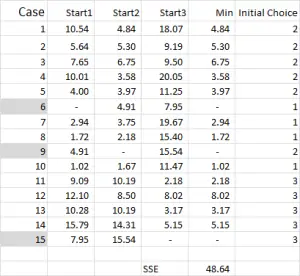
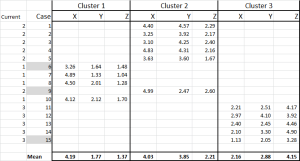
For this walk-through example, let’s assume that we want to identify three segments/clusters only. Yes, there are four clusters evident in the diagram above, but that only looks at two of the variables. Please note that you can use this Excel approach to identify as many clusters as you like – just follow the same concept as explained below. Figure 4
For k-means clustering you typically pick some random cases (starting points or seeds) to get the analysis started.
In this example – as I’m wanting to create three clusters, then I will need three starting points. For these start points I have selected cases 6, 9 and 15 – but any random points could also be suitable.
The reason I selected these cases is because – when looking at variable X only – case 6 was the median, case 9 was the maximum and case 15 was the minimum. This suggests that these three cases are somewhat different to each other, so good starting points as they are spread out.
Referring to the table output – this is our first calculation in Excel and it generates our “initial choice” of clusters. Start 1 is the data for case 6, start 2 is case 9 and start 3 is case 15. You should note that the intersection of each of these gives a 0 (-) in the table.
How does the calculation work?
alt=»cluster analysis calculation» width=»» height=»» /> Figure 5
Let’s look at the first number in the table – case 1, start 1 = 10.54.
Remember that we have arbitrarily designated Case 6 to be our random start point for Cluster 1. We want to calculate the distance and we use the sum of squares method – as shown here. We calculate the difference between each of the three data points in the set, and then square the differences, and then sum them.
We can do it “mechanically” as shown here – but Excel has a built-in formula to use: SUMXMY2 – this is far more efficient to use.
Referring back to Figure 4, we then find the minimum distance for each case from each of the three start points – this tells us which cluster (1, 2 or 3) that the case is closest to – which is shown in the ‘initial choice column’.
Step Four – Calculate the mean (average) of each cluster set
Figure 6
We have now allocated each case to its initial cluster – and we can lay that out using an IF statement in a table (as shown in Figure 6).
At the bottom of the table, we have the mean (average) of each of these cases. N0w – instead of relying on just one “representative” data point – we have a set of cases representing each.
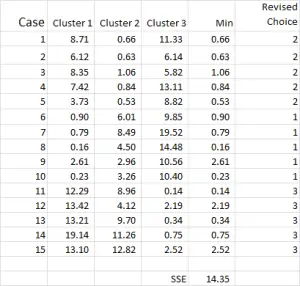
Step Five – Repeat Step 3 – the Distance from the revised mean
Figure 7
The cluster analysis process now becomes a matter of repeating Steps 4 and 5 (iterations) until the clusters stabilize.
Each time we use the revised mean for each cluster. Therefore, Figure 7 shows our second iteration – but this time we are using the means generated at the bottom of Figure 6 (instead of the start points from Figure 1).
You can now see that there has been a slight change in cluster application, with case 9 – one of our starting points – being reallocated.
You can also see sum of squared error (SSE) calculated at the bottom – which is the sum of each of the minimum distances. Our goal is to now repeat Steps 4 and 5 until the SSE only shows minimal improvement and/or the cluster allocation changes are minor on each iteration.
Final Step – Graph and Summarize the Clusters
Figure 8
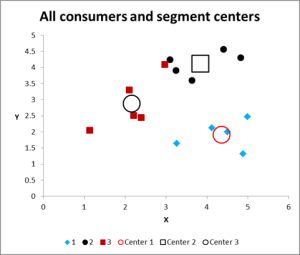
After running multiple iterations, we now have the output to graph and summarize the data.
Here is the output graph for this cluster analysis Excel example.
As you can see, there are three distinct clusters shown, along with the centroids (average) of each cluster – the larger symbols.
We can also present this data in a table form if required, as we have worked it out in Excel.
Please have a look at the case in Cluster 3 – the small red square right next to the black dot in the top middle of the graph. That case sits there because of the influence of the third variable, which is not shown on this two variable chart.
Кластерная столбчатая диаграмма в Excel | Как сделать кластерную столбчатую диаграмму?
Кластерная столбчатая диаграмма в Excel — это столбчатая диаграмма, которая представляет данные виртуально в вертикальных столбцах поочередно, хотя эти диаграммы весьма ординарны в разработке, но эти диаграммы также трудно узреть зрительно, если есть одна категория с несколькими сериями для сопоставления, тогда она просто просматривать по данной нам диаграмме, но по мере роста категорий становится весьма трудно рассматривать данные при помощи данной нам диаграммы.
Что такое кластерная столбчатая диаграмма в Excel?
До этого чем сходу перейти к «Кластеризованной столбчатой диаграмме в Excel», нам просто необходимо поначалу посмотреть на ординарную столбчатую диаграмму. Столбчатая диаграмма представляет данные в виде вертикальных полос, смотрящих на диаграмму по горизонтали. Как и остальные диаграммы, столбчатая диаграмма имеет ось X и ось Y. Обычно ось X представляет год, периоды, имена и т. Д., А ось Y представляет числовые значения. Столбчатые диаграммы употребляются для отображения широкого диапазона данных для демонстрации отчета высокому управлению компании либо конечному юзеру.
Ниже приведен обычной пример столбчатой диаграммы.
Кластеризованный столбец против столбчатой диаграммы
Обычная разница меж столбчатой диаграммой и кластерной диаграммой заключается в количестве применяемых переменных. Если количество переменных больше одной, то мы называем это «КЛАСТЕРИРОВАННАЯ ДИАГРАММА СТОЛБЦА», если количество переменных ограничено одной, мы называем это «СТОЛБЕЦ ДИАГРАММЫ».
Очередное принципиальное отличие заключается в том, что в столбчатой диаграмме мы сравниваем одну переменную с таковым же набором иной переменной. Но в диаграмме Excel с кластеризованными столбцами мы сравниваем один набор переменных с иным набором переменных, также снутри той же переменной.
Таковым образом, эта диаграмма ведает историю почти всех переменных, а столбчатая диаграмма указывает историю лишь одной переменной.
Как сделать кластерную столбчатую диаграмму в Excel?
Сгруппированная столбчатая диаграмма Excel весьма ординарна и комфортна в использовании. Давайте разберемся в работе с некими примерами.
Вы сможете скачать этот шаблон Excel для кластерной столбчатой диаграммы тут — Шаблон для кластерной столбчатой диаграммы для Excel
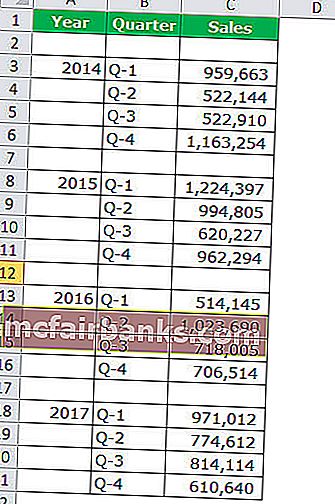
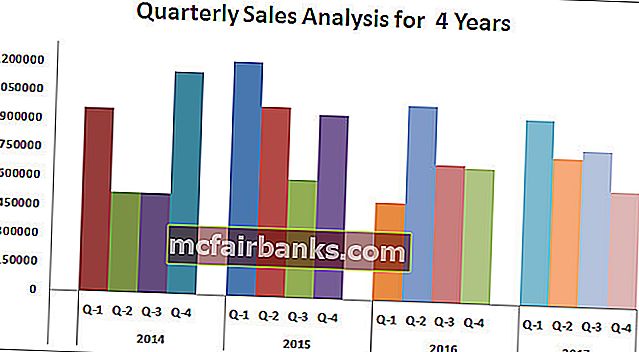
Пример # 1 Годичный и квартальный анализ продаж
Шаг 1. Набор данных должен смотреться последующим образом.
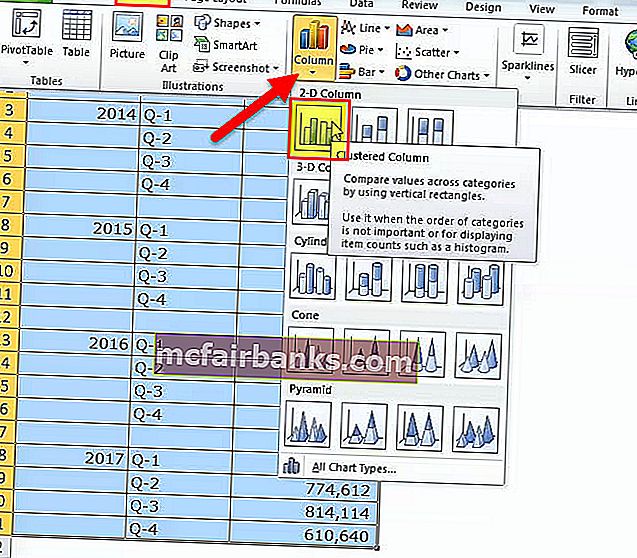
Шаг 2: Изберите данные > Перейти к вставке > Столбчатая диаграмма > Кластерная столбчатая диаграмма.
Как вы вставите диаграмму, она будет смотреться так.
Шаг 3. Сделайте форматирование, чтоб аккуратненько расположить диаграмму.
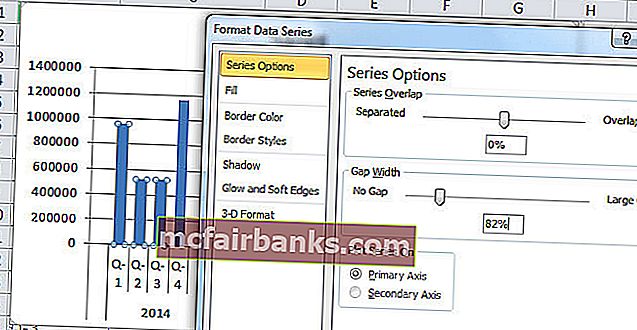
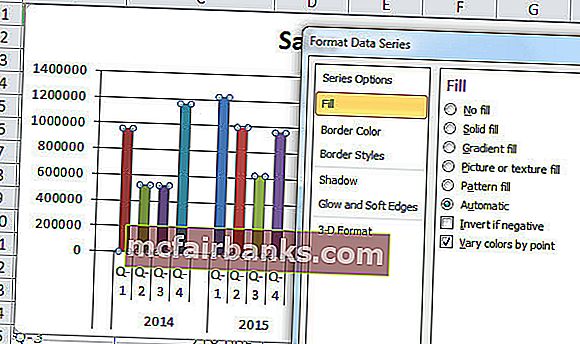
Выделите полосы и нажмите Ctrl + 1 (не запамятовывайте, что Ctrl +1 — это ярлычек для форматирования).
Нажмите на заливку и изберите вариант ниже.
Опосля конфигурации любая полоса с разной цветовой диаграммой будет смотреться последующим образом.
Таблица форматирования:
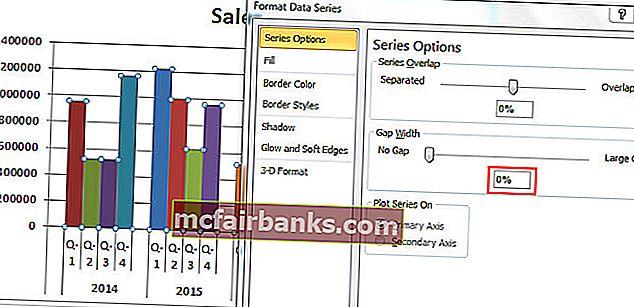
- Опосля этого сделайте зазор меж столбиками колонны до 0%.
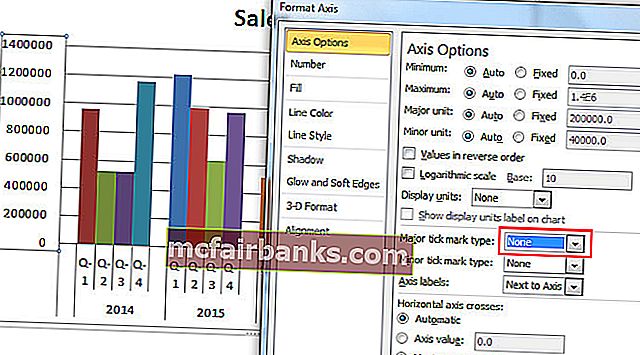
- Щелкните Axis и изберите для основного типа отметки значение «Нет».
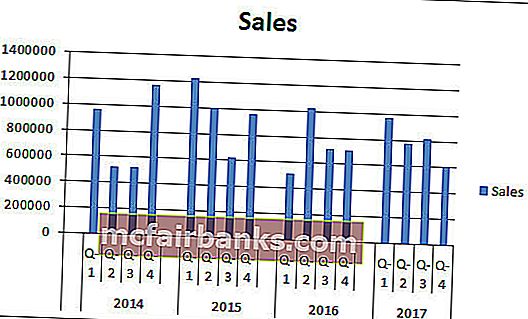
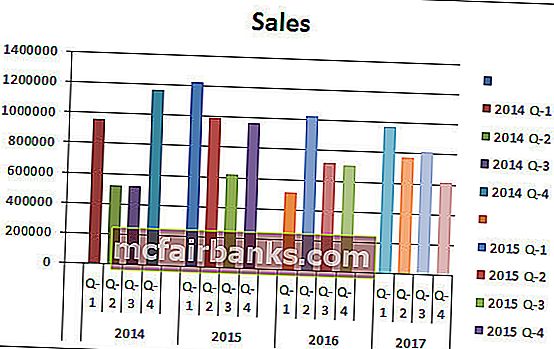
В итоге наша кластерная диаграмма будет смотреться так.
Интерпретация диаграммы:
- 1-ый квартал 2015 года — это самый высочайший период продаж, когда он принес наиболее 12 лакхов выручки.
- 1-ый квартал 2016 года — самая низкая точка по получению выручки. В этом определенном квартале было произведено всего 5,14 лакха.
- В 2014 году опосля удручающих результатов во 2-м и 3-ем кварталах наблюдается резкий рост выручки. В истинное время выручка этого квартала является вторым по величине периодом выручки.
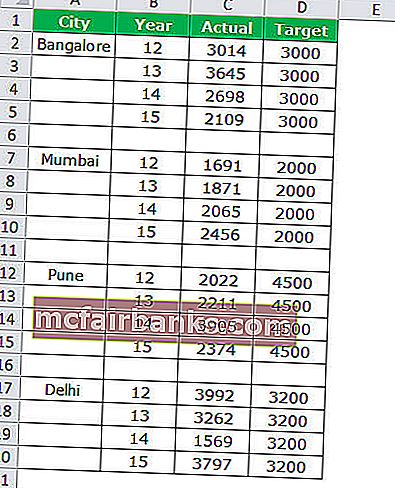
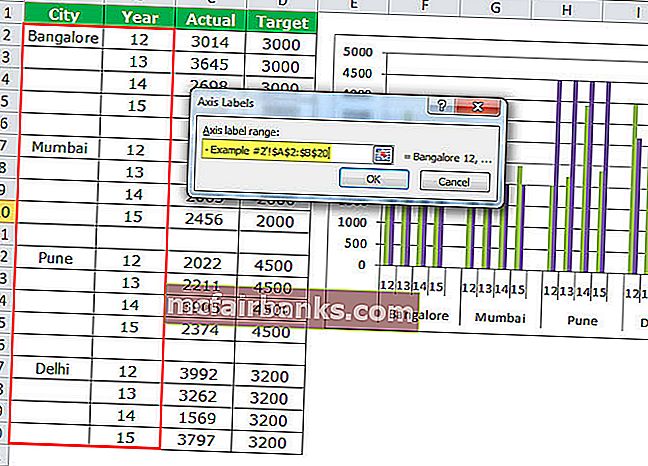
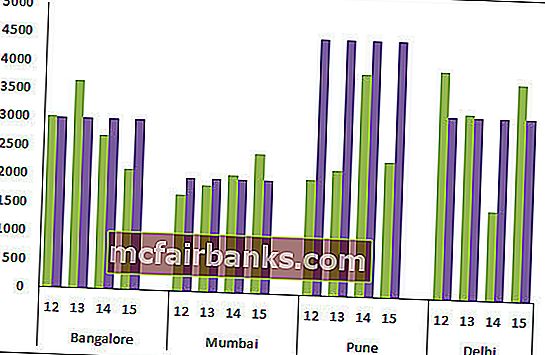
Пример # 2 Мотивированной и фактический анализ продаж в различных городках
Шаг 1. Расположите данные в формате ниже.
Шаг 2: Вставьте диаграмму из раздела вставки. Следуйте предшествующим примерам шагов, чтоб вставить диаграмму. Вначале ваш график смотрится так.
Сделайте форматирование, выполнив последующие шаги.
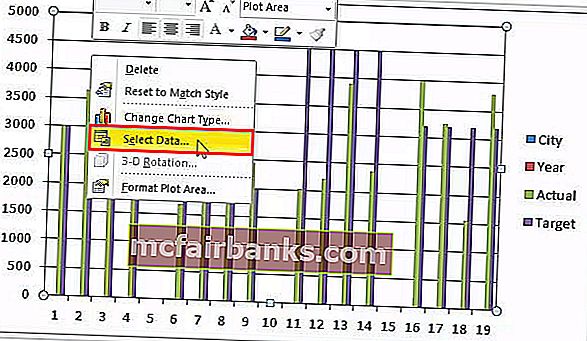
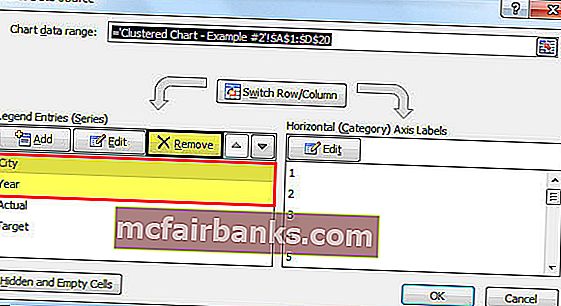
- Щелкните правой клавишей мыши диаграмму и изберите Избрать данные.
- Удалите CITY & YEAR из перечня.
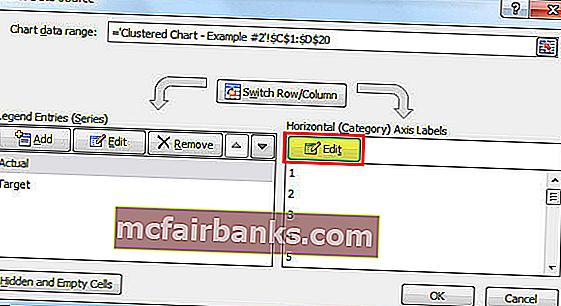
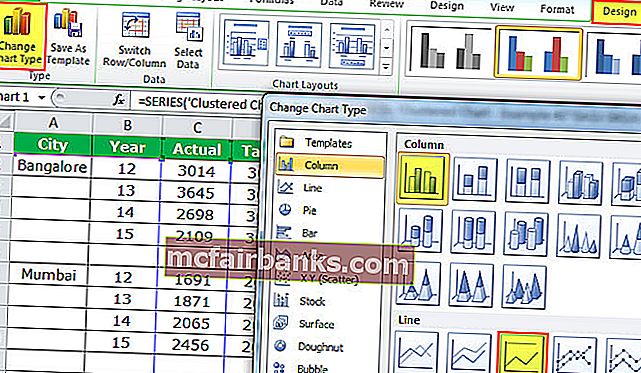
- Нажмите на опцию ИЗМЕНИТЬ и изберите ГОРОД и ГОД для данной нам серии.
- Итак, сейчас ваша диаграмма будет смотреться так.
- Примените к формату, как мы сделали в прошлом, и опосля этого ваша диаграмма будет смотреться так.
- Сейчас измените гистограмму TARGET с столбчатой диаграммы на линейную.
- Изберите Мотивированную линейчатую диаграмму и изберите « Дизайн»> «Поменять тип диаграммы»> «Избрать линейную диаграмму».
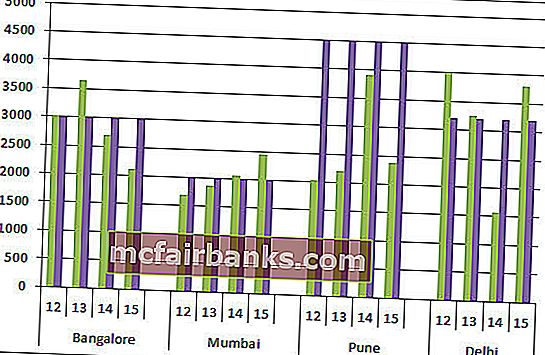
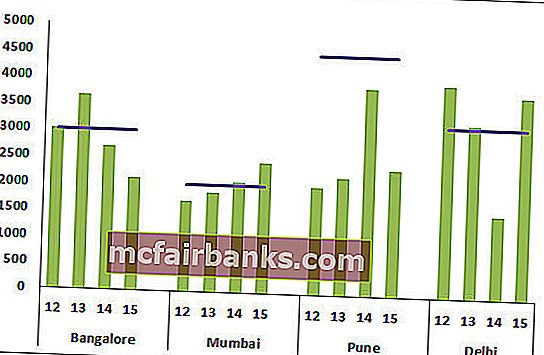
- В конце концов, наша диаграмма смотрится так.
Интерпретация диаграммы:
- Голубая линия показывает мотивированной уровень для всякого городка, а зеленоватые полосы указывают фактические значения продаж.
- Пуна — это город, где ни один год не достигнул цели.
- Кроме Пуны, цели не раз производились городками Бангалор и Мумбаи.
- Престижность! В Разделяй для заслуги цели 3 года из 4.
Пример # 3 Квартальная производительность служащих по регионам
Примечание: давайте создадим это без помощи других, и диаграмма обязана быть похожа на приведенную ниже.