Как создать подборку в Excel при помощи формул массива
При помощи средств Excel можно производить подборку определенных данных из спектра в случайном порядке, по одному условию либо нескольким. Для решения схожих задач употребляются, обычно, формулы массива либо макросы. Разглядим на примерах.
Как создать подборку в Excel по условию
При использовании формул массива отобранные данные показываются в отдельной таблице. В чем и состоит преимущество данного метода в сопоставлении с обыденным фильтром.
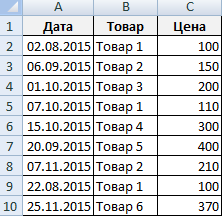
Поначалу научимся созодать подборку по одному числовому аспекту. Задачка – избрать из таблицы продукты с ценой выше 200 рублей. Один из методов решения – применение фильтрации. В итоге в начальной таблице останутся лишь те продукты, которые удовлетворяют запросу.
Иной метод решения – внедрение формулы массива. Надлежащие запросу строчки поместятся в отдельный отчет-таблицу.
Поначалу создаем пустую таблицу рядом с начальной: дублируем заглавия, количество строк и столбцов. Новенькая таблица занимает спектр Е1:G10.Сейчас выделяем Е2:Е10 (столбец «Дата») и вводим последующую формулу: < >.
Чтоб вышла формула массива, жмем сочетание кнопок Ctrl + Shift + Enter. В примыкающий столбец – «Продукт» — вводим аналогичную формулу массива: < >. Поменялся лишь 1-ый аргумент функции ИНДЕКС.
В столбец «Стоимость» введем такую же формулу массива, изменив 1-ый аргумент функции ИНДЕКС.
В итоге получаем отчет по товарам с ценой больше 200 рублей.
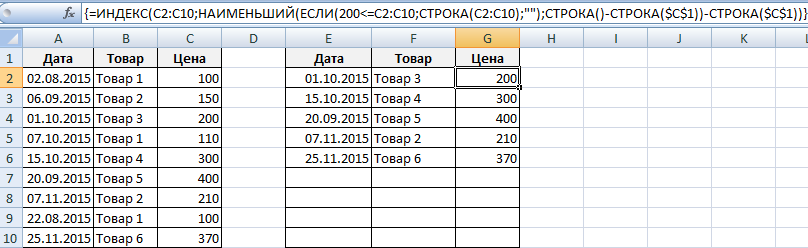
Таковая выборка является оживленной: при изменении запроса либо возникновении в начальной таблице новейших продуктов, автоматом обменяется отчет.
Задачка №2 – избрать из начальной таблицы продукты, которые поступили в продажу 20.09.2015. Другими словами аспект отбора – дата. Для удобства разыскиваемую дату введем в отдельную ячейку, I2.
Для решения задачки употребляется подобная формула массива. Лишь заместо аспекта >.
Подобные формулы вводятся и в остальные столбцы (принцип см. выше).
Сейчас используем текстовый аспект. Заместо даты в ячейку I2 введем текст «Продукт 1». Мало изменим формулу массива: < >.
Таковая большая функция подборки в Excel.
Выборка по нескольким условиям в Excel
Поначалу возьмем два числовых аспекта:
Задачка – отобрать продукты, которые стоят меньше 400 и больше 200 рублей. Объединим условия знаком «*». Формула массива смотрится последующим образом: < =C2:C10);СТРОКА(C2:C10);"");СТРОКА(C2:C10)-СТРОКА($C$1))-СТРОКА($C$1))' >>.
Это для первого столбца таблицы-отчета. Для второго и третьего – меняем 1-ый аргумент функции ИНДЕКС. Итог:
Чтоб создать подборку по нескольким датам либо числовым аспектам, используем подобные формулы массива.
Случайная выборка в Excel
Когда юзер работает с огромным количеством данных, для следующего их анализа может потребоваться случайная выборка. Любому ряду можно присвоить случайный номер, а потом применить сортировку для подборки.
Начальный набор данных:
Поначалу вставим слева два пустых столбца. В ячейку А2 впишем формулу СЛЧИС (). Размножим ее на весь столбец:
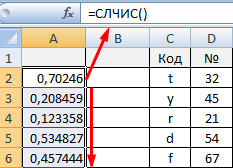
Сейчас копируем столбец со случайными числами и вставляем его в столбец В. Это необходимо для того, чтоб эти числа не изменялись при внесении новейших данных в документ.
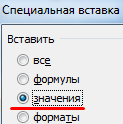
Чтоб вставились значения, а не формула, щелкаем правой клавишей мыши по столбцу В и избираем инструмент «Особая вставка». В открывшемся окне ставим галочку напротив пт «Значения»:
Сейчас можно отсортировать данные в столбце В по возрастанию либо убыванию. Порядок представления начальных значений тоже поменяется. Избираем хоть какое количество строк сверху либо снизу – получим случайную подборку.
Выборка данных из таблиц
Для юзера баз данных основное суметь их считывать. Но, сам формат данных в виде базы не комфортен для восприятия конечного юзера, потому считывание делается на базе подборки подходящих данных из таблицы либо связанных таблиц.
Подборкой управляет программер при помощи аннотации SELECT. Таблица либо таблицы из которых делается выборка именуются начальным набором (данных) а итог подборки, новенькая таблица – результирующим набором.
Простая форма SELECT
Представляет собой одиночный оператор без указания начального набора очевидно. К примеру:
Результатом выполнения таковой подборки будет таблица с 3-мя значениями.
Но обычно оператор применяется совместно с FROM, который показывает на начальный набор:
Как видно из примера выше: столбцы, которые должны попасть в результирующий набор перечисляются через запятую.
Если SELECT делает подборку из нескольких таблиц, то не считая столбца необходимо указать и таблицу, которой он принадлежит:
Либо с внедрением псевдонимов:
Чтоб извлечь все строчки из таблицы либо таблиц используйте символ *
Общая форма запроса
Смотрится последующим образом:
Ее лучше уяснить, так как она показывает порядок следования инструкций снутри SELECT. Нарушать этот порядок недозволено.
Каждое предложение отвечает за собственные манипуляции с начальным набором:
- Where применяется для фильтрации;
- GROUP BY и HAVING – для подготовительной группировки;
- ORDER BY – для сортировки по возрастанию либо убыванию.
Предложение WHERE
Применяется чтоб задать условие для подборки. Используются как обыкновенные условия, так и составные. Снутри SELECT постоянно следует опосля предложения FROM.
Последующий код создаст таблицу, куда входят лишь жильцы чей номер квартиры больше 10:
Добавим условие для наиболее сложного фильтра подборки:
Соединение критерий делается на базе логических операторов:
- AND – логическое И;
- OR – логическое ИЛИ;
- NOT – логическое НЕ.
Допустимо употреблять и арифметические операции, основное, чтоб их итог был логическими «ДА» и «НЕТ», другими словами true либо false.
Ключевое слово DISTINCT
Когда в итоге подборки попадаются дубликаты данных по столбцу применяется ключевое слово DISTINCT. В структуре запроса оно прописывается конкретно опосля SELECT. DISTINCT удаляет дубликаты.
Чтоб узреть его внедрение добавим в базу новейшую строчку:
Сейчас выведем создадим подборку по номерам квартир и фамилиям, с условием что номер квартиры должен быть больше 10:

В итоге получаем дубликат в столбце apartmentnumber.
Чтоб этого избежать применим аннотацию SELECT c главным словом DISTINCT:
Если применить ключевое слово DISTINCT к нескольким столбцам, то в результирующую коллекцию не попадут лишь дубликаты по всем включенным столбцам.
Фильтр по шаблону
Неважно какая база данных содержит символьные данные и даты. В нашей таблице – это столбцы housemateName и BithDate. Фильтрация по сиим столбцам постоянно связана с внутренней аннотацией поиска. Эту аннотацию реализует оператор LIKE.
LIKE сформировывает шаблон. Шаблон – это строковая константа либо дата. Оператор WHERE отыскивает совпадения шаблона и настоящих данных в таблице. Шаблон составляется на базе подстановочных знаков. Самые нередко применяемые:
- _ — хоть какой единичный знак;
- % — последовательность хоть какой длины;
- [] — указывается спектр значений «от … до».
Ключевое слово LIKE в структуре запроса постоянно следует опосля WHERE:
Результатом запроса выше будет таблица обитателей, в фамилии который 3-я буковка м.
Последующий запрос возвратит таблицу с фамилиями, 1-ая буковка которых находится в спектре алфавита от A до Г:
Допустимо составлять многоуровневые фильтрации с несколькими блоками LIKE:
[Расширение] Загрузка данных из Excel в табличную часть документа с созданием не отысканной номенклатуры







4. У расширения "Загрузка данных из наружных файлов" убрать галку " Неопасный режим ".
5. Клавиша "Перезапустить"
6. Готово! Пробуем.
{Инструкция} по подключению расширения с картинами: //buhstart.com/public/442003/#Join
Опосля подключения расширения необходимо снять галку "Неопасный режим" и перезапустить программку (см. изображения к публикации)
UPD 25.06.17
Исправлена ошибка: сейчас при разработке номенклатуры "Тип номенклатуры" берется из поля "Вид номенклатуры"
UPD 27.06.17
Исправлена ошибка: при проведении документа выходила ошибка не заполнен склад.
Добавлено: у отысканной номенклатуры проставляется поле "Группа"
UPD 13.07.17
Добавлено: возможность загрузки в документ "Перемещение продуктов"
PS Испытана загрузка в документы: Поступление продуктов, Заказ клиенту, Заказ Поставщику, Перемещение продуктов, Реализация продуктов и услуг. (вероятна загрузка в остальные документы, где есть таблица Продукты). Если желаете загружать в остальные документы пишите, проверю либо качайте и смотрите сами.
UPD 27.08.19
Заместо обработки сейчас употребляется расширение конфигурации(cfe). В связи с сиим данная разработка работает всюду, где есть пункт меню "Загрузить из наружного файла". Проверялось на версии УТ 11.4.9.70. На наиболее ранешних версиях работа не гарантируется(необходимо инспектировать).
UPD 02.06.20
1. Добавлено 2-ое расширение ПеремещениеСписаниеОприходование.cfe для прибавления клавиши "Загрузка из внеш файла" в надлежащие документы. (сейчас можно загружать продукты в документы Перемещение продуктов, Списание недостач продуктов, Оприходование излишков продуктов).
Если для вас не нужно функции загрузки данных из внеш файла в данные документы, то расширение устанавливать не нужно.
2. Обновил расширения ПеремещениеСписаниеОприходование.cfe и ЗагрузкаДанныхИзВнешнихФайлов.cfe для УТ 11.4.12 в связи с тем, что "1С" изменила режим сопоставимости с версии "8.3.12" на версию "8.3.14"
Для доработки загрузки в документы поступление, списание, оприходование употреблял код из //buhstart.com/public/1224859/
UPD 13.10.20
Расширение приспособлено под редакцию УТ 11.4.13
UPD 25.01.21
Добавил возможность конфигурации "Группы" номенклатуры в таблице без захода в карточку "Номенклатуры".
Добавил в шапку "Производитель" для сотворения номенклатуры с необходимым производителем.
Excel выборка данных из таблицы
Большущее количество данных в мире хранится в базах данных. Для управления данными, в том числе для извлечения данных, почаще всего употребляют язык структурированных запросов SQL (Structured Query Language). Если вы желаете стать аналитиком данных, то для вас нужны практические познания в области баз данных и SQL. Цель этого курса — познакомиться с концепциями реляционных баз данных, изучить базы языка SQL и научиться использовать эти познания на практике. Также вы научитесь использовать язык SQL для обработки и анализа данных. Этот курс нацелен на практическое применение. Потому вы будете работать с настоящими базами и наборами данных, употреблять настоящие инструменты обработки и анализа данных Вы создадите экземпляр базы данных в облаке. Выполняя лабораторные работы, вы попрактикуетесь в разработке и выполнении SQL-запросов. Вы также узнаете, как получить доступ к базам данных из среды Jupyter при помощи языков SQL и Python. Начальные познания о базах данных, SQL, Python и программировании не требуются. Хоть какой желающий может пройти этот курс безвозмездно. Если вы пройдете этот курс и получите сертификат Coursera, вы также сможете получить цифровой значок IBM. ОГРАНИЧЕННОЕ ПРЕДЛОЖЕНИЕ: приобретите подписку всего за 39 долл. США (Соединённые Штаты Америки — государство в Северной Америке) за месяц и получите доступ к упорядоченным по уровням материалам и сертификат по окончании курса.
您将学习的技能
Grouped Data, Euler'S Totient Function, Relational Database, SQL
Неделька 2. Расширенные SQL-запросы
Завершив исследование модуля, вы будете знать: (1) Как употреблять строковые шаблоны и спектры для поиска данных, также как сортировать и группировать данные в результирующей выборке. (2) Как работать с несколькими таблицами в реляционной базе данных при помощи операторов JOIN.

Hima Vasudevan

Rav Ahuja
Global Program Director
Hello, and welcome to sorting SELECT statement results sets. In this video, we will learn about some advanced techniques in retrieving data from a relational database table and sorting how the result set displays. At the end of this lesson, you will be able to describe how to sort the result set by either ascending or descending order and explain how to indicate which column to use for the sorting order. The main purpose of a database management system is not just to store the data, but also facilitate retrieval of the data. In its simplest form, a select statement is select * from table name. Based on our simplified library database model, in the table book, select * from book gives a result set of four rows. All the data rows for all columns in the table book are displayed. We can choose to list the book titles only as shown in this example, select title from book. However, the order does not seem to be in any order. Displaying the results set in alphabetical order would make the result set more convenient. To do this, we use the "order by" clause. To display the result set in alphabetical order, we add the order by clause to the select statement. The order by clause is used in a query to sort the result set by a specified column. In this example, we have used order by on the column title to sort the result set. By default, the result set is sorted in ascending order. In this example, the result set is sorted in alphabetical order by book title. To sort in descending order, use the key word" desc." The result set is now sorted according to the column specified, which is title, and is sorted in descending order. Notice the order of the first three rows. The first three words of the title are the same, so the sorting starts from the point where the characters differ. Another way of specifying the sort column is to indicate the column sequence number. In this example, select title, pages from book, order by two, indicates the column sequence number in the query for the sorting order. Instead of specifying the column name pages, the number two is used. In the select statement, the second column specified in the column list is pages, so the sort order is based on the values in the pages column. In this case, the pages column indicates the number of pages in the book. As you can see, the result set is in ascending order by number of pages. Now you can describe how to sort the result set by either ascending or descending order, and explain how to indicate which column to use for the sorting order. Thanks for watching this video.