Как создать парсер веб-сайта без помощи других (текстовая {инструкция} видео)
Как создать парсер веб-сайта без помощи других (текстовая {инструкция} +видео)
2) массово выгружать информацию из категорий продуктов.
3) выгружать данные в файлы YML,Excel,CSV,JSON.
Видео-инструкция по созданию парсера
Создадите настройку для новейшего парсера
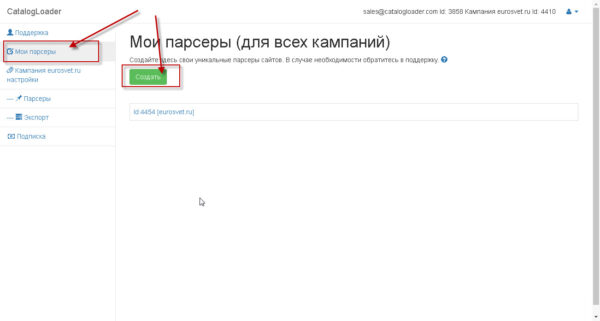
На последующем шаге введите ссылку на карточку продукта и на категорию
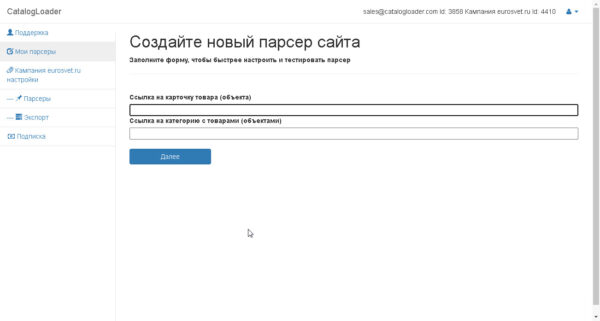
Для примера ввели ссылки для веб-сайта eurosvet.ru
Карточка продукта
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki/podvesnoy-svetilnik-so-steklyannym-plafonom-50208-1-yantarnyy-a052491
Ссылка на категорию
https://eurosvet.ru/catalog/lustri/podvesnye-svetilniki
и нажмите на клавишу «Дальше»
и вы попадете на страничку где будет настраиваться парсер для вашего определенного веб-сайта.
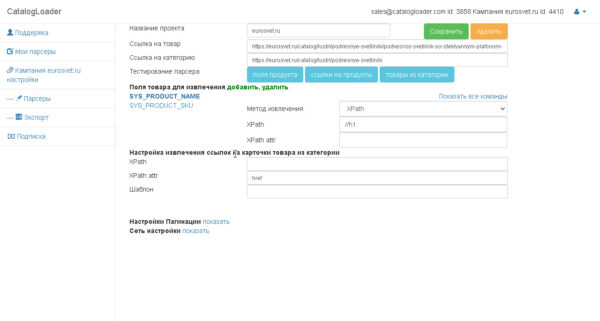
Настройка парсера
Можно выделить последующие этапы в настройке парсера веб-сайта:
1. Настройка извлечения полей для определенного продукта.
2. Настройка извлечения ссылок на карточки продуктов из группы.
3. Настройка пагинаций (на британском pagination).
1. Настройка извлечения полей для определенного продукта.
Принципиально! как вы настроили поле, то тестируйте его извлечение через клавишу «Поля продукта».
И вы увидите как отработает парсер для вашего продукта.
Блок, который отвечает за извлечение полей — отмечен на картинке: 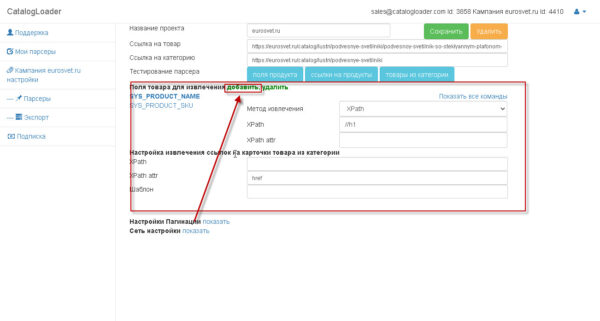
чтоб добавить новейшие поле -нажимайте на клавишу «добавить», если нужно удалить,то ,сначала, нужно выделить соответственное поле, а позже кликнуть на подобающую клавишу.
На последующей картинке показан диалог прибавления новейших полей. 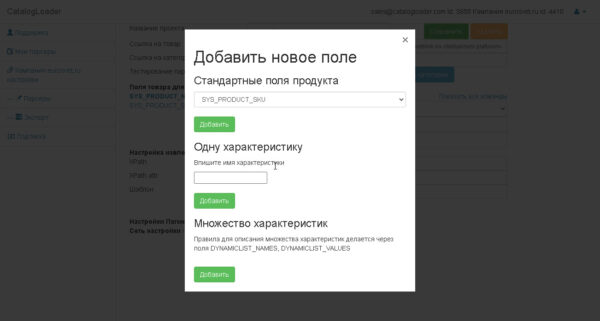
Есть 3 вида полей.
1) обыкновенные(базисные). — SYS_PRODUCT_SKU, SYS_PRODUCT_NAME, SYS_PRODUCT_MANUFACTURER и т.д.
это соответствунно Артикул, имя и производитель продукта.
SYS_PRODUCT_IMAGES_ALL — это поле куда обязано быть записаны все рисунки продукта.
2) свойства.-определяются свойства продукта, к примеру, заглавие вы сможете задать без помощи других.
3) динамические свойства. Это тоже задает извлечение черт из таблицы значений.
для этого необходимо будет задать DYNAMICLIST_NAMES, DYNAMICLIST_VALUES поля таковым образом чтоб количество извлекаемых заглавий и значений было идиентично.
Как извлекать значения
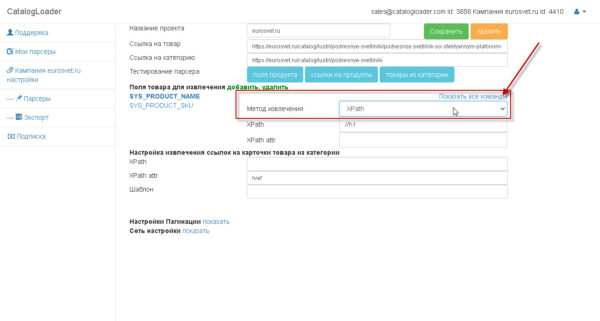
Для хоть какого поля можно указать как оно будет извлекаться.
Есть два варианта:
1)Xpath
2)RegEx (Regular Expresstion)- постоянное выражение.
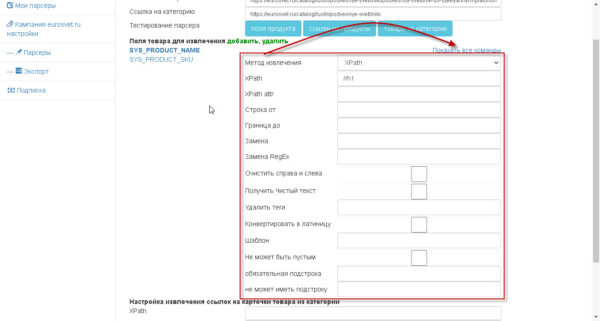
добавочно к командам можно добавить доп обработку.
2. Настройка извлечения ссылок на карточки продуктов из группы.
Принципиально! как вы настроили «извлечение ссылок на карточки товаров из группы», то тестируйте его извлечение через клавишу «ссылки на продукты». И вы увидите как отработает парсер для вашей группы. Ссылки соберутся без пагинаций.
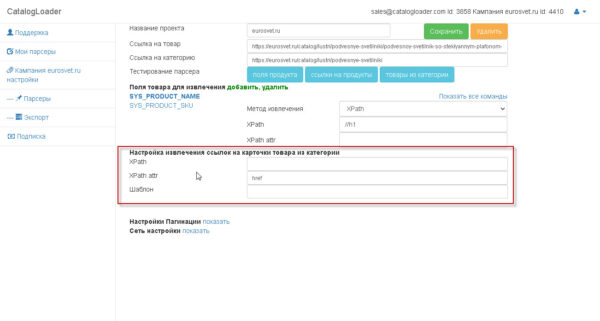
поле «Шаблон» в данной для нас области необходимо для того чтоб задать абсолютный путь для ссылки,если это нужно. Обычно оставляется пустым.
3. Настройка пагинаций (на британском pagination).
Если вы уже дошли ранее шага, то это означает что вы уже сделали 90% работы. Опосля окончания опций по пагинации чтоб протестировать парсер нужно будет надавить на клавишу «продукты из группы».
есть два варианта как настраивать пагинацию
1. через шаблон 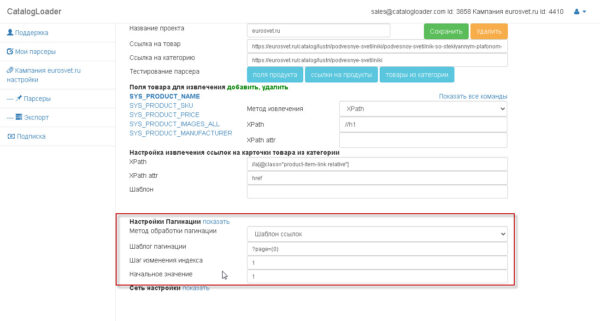
2. через «последующую ссылку» 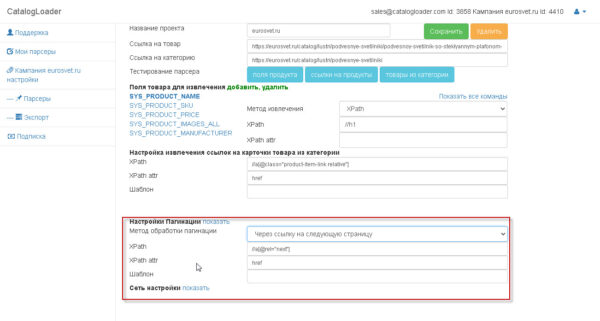
Что такое «последующая ссылка» для вас поможет осознать последующее изображение: 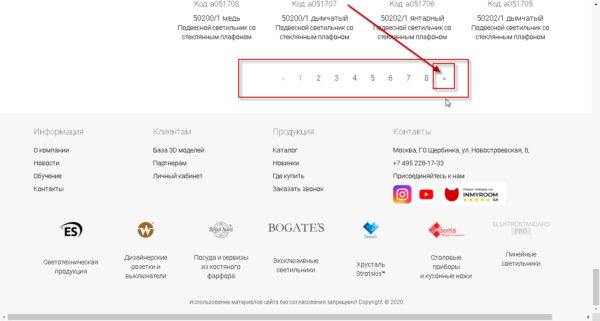
т.е. та ссылка, которая описывает переход из текущей странички каталога на последующую.
Как запускать парсер
Есть два метода:
1) из опций парсера, методом нажатия на клавишу «продукты из группы»
2) из вкладки «Экспорт», методом нажатия на клавишу «запустить экспорт»
два этих метода предложат для вас последующий экран, на котором нужно будет задать откуда брать «входные» ссылки
для старта парсера
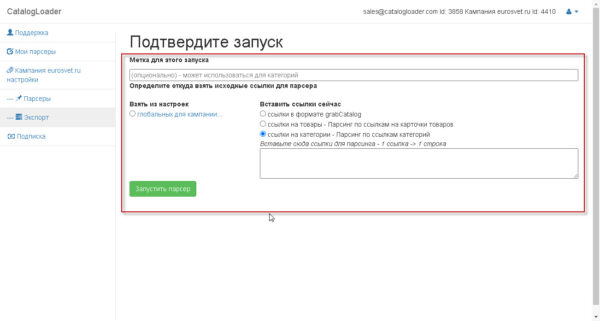
в самом ординарном варианте использования, вы на любой пуск описывает ссылка либо на карточки продуктов либо на группы,выбирая соответственный режим работы.
Если нужно задать статический перечень либо карточек продуктов либо категорий, то для этого нужно задать grabCatalog файл через глобальные опции кампании один раз, а позже уже применять любой последующий раз вручную либо через пуск по-расписанию парсера.
Что такое grabCatalog формат
Это текстовый файл, который описывает
1)иерархию категорий, которая будет извлекаться
2)наименования и ссылки (опционально) на группы, которые будет извлекаться
3)ссылки на карточки продуктов (опционально).
принципиально знать о формате
# — (символ Сетка) — описывает уровень иерархии
[path] — отделяет имя группы от ссылки на категорию
пример : 1 категория будет парсится
пример : 2 группы будет парсится
пример : 2 группы будет парсится, но они заданы как подкатегории 1 группы верхнего уровня.
пример : заданы 2 ссылки на продукт (задаются опосля наименования группы).
Как настроить выгрузку данных в определенный тип файла
Лаконичный Урок-введение в Xpath для парсинга веб-сайтов с примерами.
Для выбора тегов и наборов тегов в HTML документе XPath употребляет выражения путей. Тег Извлекается следуя по данному пути либо по, так именуемым, шагам.
Пример HTML файла
Для примера будет употребляться последующий HTML файл

Выбор тегов (как извлечь определенные теги через XPath)
Чтоб извлечь теги в HTML документе, XPath употребляет выражения. Тег Извлекается по данному пути. Более полезные выражения пути:
| Xpath Выражение | Итог |
|---|---|
| имя_тега | Извлекает все узлы с именованием «имя_тега» |
| / | Извлекает от корневого тега |
| // | Извлекает узлы от текущего тега, соответственного выбору, независимо от их местопребывания |
| . | Извлекает текущий узел |
| .. | Извлекает родителя текущего тега |
| @ | Извлекает атрибуты |
Некие подборки по HTML документу из примера:
| Xpath Выражение | Итог |
|---|---|
| messages | Извлекает все узлы с именованием «messages» |
| /messages | Извлекает корневой элемент сообщений Принципиально знать!: Если путь начинается с косой черты ( / ), то он постоянно представляет абсолютный путь к элементу! |
| messages/note | Извлекает все элементы note, являющиеся потомками элемента messages |
| //note | Извлекает все элементы note независимо от того, где в документе они находятся |
| messages//note | Извлекает все элементы note, являющиеся потомками элемента messages независимо от того, где они находятся от элемента messages |
| //@date | Извлекает все атрибуты с именованием date |
Предикаты
Предикаты разрешают отыскать определенный Тег либо Тег с определенным значением.
Предикаты постоянно заключаются в квадратные скобки [].
В последующей таблице приводятся некие выражения XPath с предикатами, дозволяющие создать подборки по HTML документу из примера
| Xpath Выражение | Итог |
|---|---|
| /messages/note[1] | Извлекает 1-ый элемент note, который является прямым потомком элемента messages. Принципиально знать!: В IE 5,6,7,8,9 первым узлом будет [0], но согласно W3C это должен быть [1]. Чтоб решить эту делему в IE, необходимо установить опцию SelectionLanguage в значение XPath. В JavaScript: HTML.setProperty(«SelectionLanguage»,»XPath»); |
| /messages/note[last()] | Извлекает крайний элемент note, который является прямым потомком элемента messages. |
| /messages/note[last()-1] | Извлекает предпоследний элемент note, который является прямым потомком элемента messages. |
| /messages/note[position()<3] | Извлекает 1-ые два элемента note, которые являются прямыми потомками элемента messages. |
| //heading[@date] | Извлекает все элементы heading, у каких есть атрибут date |
| //heading[@date=»11/12/2020″] | Извлекает все элементы heading, у каких есть атрибут date со значением «11/12/2020» |
Выбор неведомых заблаговременно тегов
Чтоб отыскать неведомые заблаговременно узлы HTML документа, XPath дозволяет применять особые знаки.
| Спецсимвол | Описание |
|---|---|
| * | Соответствует хоть какому тегу элемента |
| @* | Соответствует хоть какому тегу атрибута |
| node() | Соответствует хоть какому тегу хоть какого типа |
Спецсимволы, пример выражения XPath со спецсимволами:
| Xpath Выражение XPath | Итог |
|---|---|
| /messages/* | Извлекает все элементы, которые являются прямыми потомками элемента messages |
| //* | Извлекает все элементы в документе |
| //heading[@*] | Извлекает все элементы heading, у каких есть по последней мере один атрибут хоть какого типа |
Если нужно избрать нескольких путей
Внедрение оператора | в выражении XPath дозволяет созодать выбор по нескольким путям.
В последующей таблице приводятся некие выражения XPath, дозволяющие создать подборки по демонстрационному HTML документу:
Интернет-скрейпинг: как безвозмездно спарсить и извлечь данные с веб-сайта
Нередко у веб-мастера, маркетолога либо SEO-специалиста возникает необходимость извлечь данные со страничек веб-сайтов и показать их в комфортном виде для предстоящей обработки. Это быть может парсинг цен в интернет-магазине, получение числа лайков либо извлечение содержимого отзывов с интересующих ресурсов.
По дефлоту большая часть программ технического аудита веб-сайтов собирают лишь содержимое заголовков H1 и H2, но, если к примеру, вы желаете собрать заглавия H5, то их уже необходимо будет извлекать раздельно. И чтоб избежать рутинной ручной работы по парсингу и извлечению данных из HTML-кода страничек – обычно употребляют веб-скраперы.
Интернет-скрейпинг – это автоматический процесс извлечения данных с интересующих страничек веб-сайта по определенным правилам.
Вероятные сферы внедрения веб-скрейпинга:
- Отслеживание цен на продукты в интернет-магазинах.
- Извлечение описаний продуктов и услуг, получение числа продуктов и картинок в листинге.
- Извлечение контактной инфы (адреса электрической почты, телефоны и т.д.).
- Сбор данных для рекламных исследовательских работ (лайки, шеры, оценки в рейтингах).
- Извлечение специфичных данных из кода HTML-страниц (поиск систем аналитики, проверка наличия микроразметки).
- Мониторинг объявлений.
Главными методами веб-скрейпинга являются способы разбора данных используя XPath, CSS-селекторы, XQuery, RegExp и HTML templates.
- XPath представляет собой особый язык запросов к элементам документа формата XML / XHTML. Для доступа к элементам XPath употребляет навигацию по DOM методом описания пути до подходящего элемента на страничке. С его помощью можно получить значение элемента по его порядковому номеру в документе, извлечь его текстовое содержимое либо внутренний код, проверить наличие определенного элемента на страничке. Описание XPath >>
- CSS-селекторы употребляются для поиска элемента его части (атрибут). CSS синтаксически похож на XPath, при всем этом в неких вариантах CSS-локаторы работают резвее и описываются наиболее наглядно и коротко. Минусом CSS будет то, что он работает только в одном направлении – вглубь документа. XPath же работает в обе стороны (к примеру, можно находить родительский элемент по дочернему). Таблица сопоставления CSS и XPath >>
- XQuery имеет в качестве базы язык XPath. XQuery имитирует XML, что дозволяет создавать вложенные выражения в таковым методом, который неосуществим в XSLT. Описание XQuery >>
- RegExp – формальный язык поиска для извлечения значений из огромного количества текстовых строк, соответственных требуемым условиям (постоянному выражению). Описание RegExp >>
- HTML templates – язык извлечения данных из HTML документов, который представляет собой комбинацию HTML-разметки для описания шаблона поиска подходящего фрагмента плюс функции и операции для извлечения и преобразования данных. Описание HTML templates >>
Обычно с помощью парсинга решаются задачки, с которыми трудно совладать вручную. Это быть может интернет скрейпинг описаний продуктов при разработке новейшего интернет-магазина, скрейпинг в рекламных исследовательских работах для мониторинга цен, или для мониторинга объявлений (к примеру, по продаже квартир). Для задач SEO-оптимизации обычно употребляются узко спец инструменты, в которых уже интегрированы парсеры со всеми необходимыми опциями извлечения главных SEO характеристик.
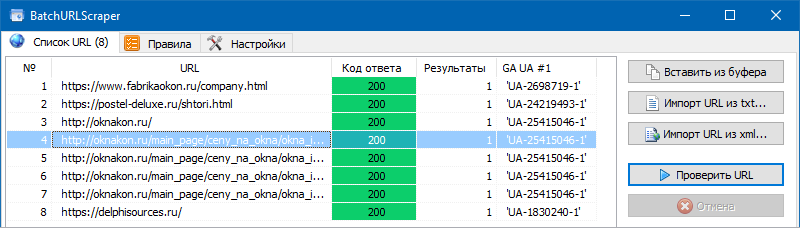
BatchURLScraper
Существует огромное количество инструментов, позволяющих производить скрейпинг (извлекать данные из сайтов), но большая часть из их платные и массивные, что несколько ограничивает их доступность для массового использования.
Потому нами был сотворен обычной и бесплатный инструмент – BatchURLScraper, созданный для сбора данных из перечня URL с возможностью экспорта приобретенных результатов в Excel.
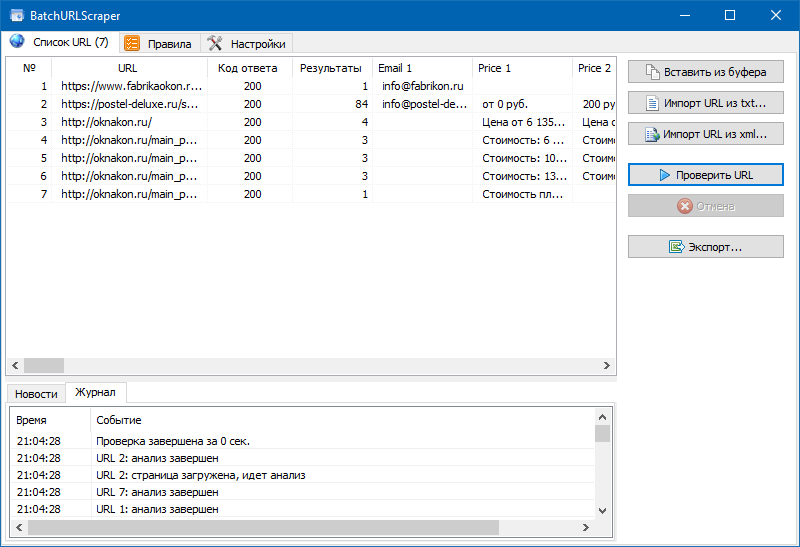
Интерфейс программки довольно прост и состоит всего из 3-х вкладок:
- Вкладка "Перечень URL" создана для прибавления страничек парсинга и отображения результатов извлечения данных с возможностью их следующего экспорта.
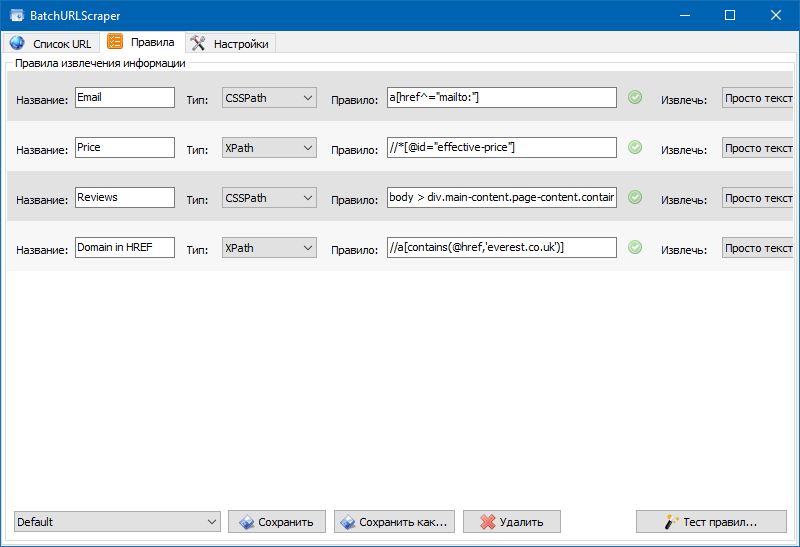
- На вкладке "Правила" делается настройка правил скрейпинга с помощью XPath, CSS-локаторов, XQuery, RegExp либо HTML templates.
- Вкладка "Опции" содержит общие опции программки (число потоков, User-Agent и т.п.).
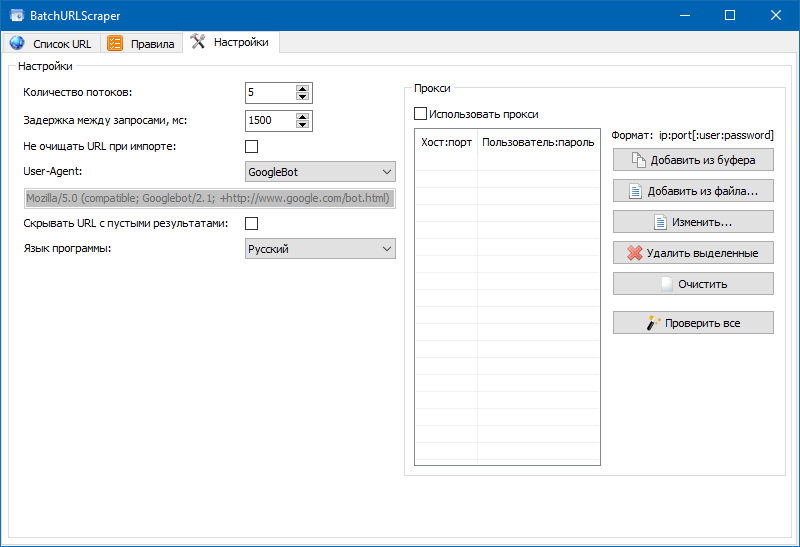
Также нами был добавлен модуль для отладки правил.
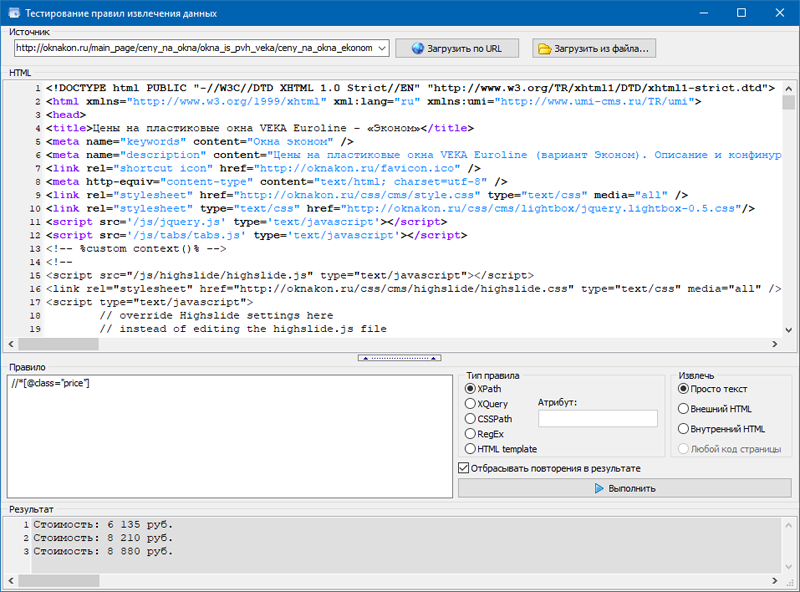
С помощью встроенного отладчика правил можно стремительно и просто получить HTML-содержимое хоть какой странички веб-сайта и тестировать работу запросов, опосля что применять отлаженные правила для парсинга данных в BatchURLScraper.
Разберем наиболее тщательно примеры опций парсинга для разных вариантов извлечения данных.
Извлечение данных со страничек веб-сайтов в примерах
Потому что BatchURLScraper дозволяет извлекать данные из случайного перечня страничек, в котором могут встречаться URL от различных доменов и, соответственно, различных типов веб-сайта, то для примеров тестирования извлечения данных мы будем применять все 5 вариантов скрейпинга: XPath, CSS, RegExp, XQuery и HTML templates. Перечень тестовых URL и опций правил находятся в дистрибутиве программки, таковым образом можно протестировать все это лично, используя пресеты (предустановленные опции парсинга).
Механика извлечения данных
1. Пример скрейпинга через XPath.
К примеру, в интернет-магазине мобильников нам необходимо извлечь цены со страничек карточек продуктов, также признак наличия продукта на складе (есть в наличии либо нет).
Для извлечения цен нам необходимо:
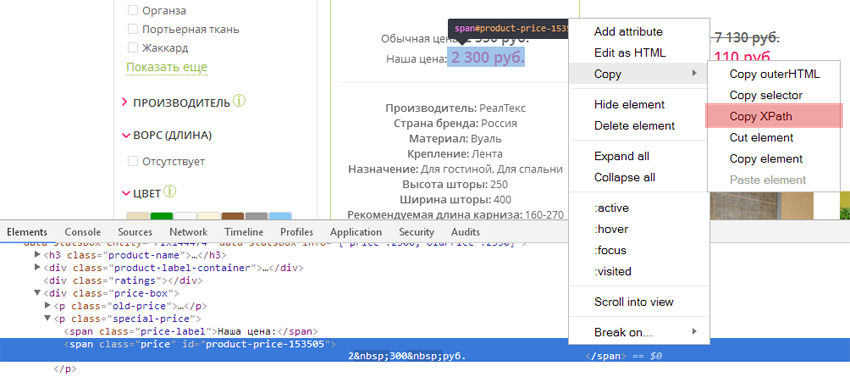
- Перейти на карточку продукта.
- Выделить стоимость.
- Кликнуть по ней правой клавишей мыши и надавить «Показать код элемента» (либо «Inspect», если вы используете английский интерфейс).
- В открывшемся окне отыскать элемент, отвечающий за стоимость (он будет подсвечен).
- Кликнуть по нему правой клавишей мыши и избрать «Копировать» > «Копировать XPath».
Для извлечения признака наличия продукта на веб-сайте операция будет аналогичной.
Потому что типовые странички обычно имеют однообразный шаблон, довольно сделать операцию по получению XPath для одной таковой типовой странички продукта, чтоб спарсить цены всего магазина.
Дальше, в перечне правил программки мы добавляем попеременно правила и вставляем в их ранее скопированные коды частей XPath из браузера.
2. Определяем присутствие счетчика Гугл Analytics с помощью RegExp либо XPath.
- XPath:
- Открываем начальный код хоть какой странички по Ctrl-U, потом отыскиваем в нем текст "gtm.start", отыскиваем в коде идентификатор UA-. и дальше также используя отображение кода элемента копируем его XPath и вставляем в новое правило в BatchURLScraper.
- Поиск счетчика через постоянные выражения еще проще: код правила извлечения данных вставляем [‘](UA-.*?)[‘].

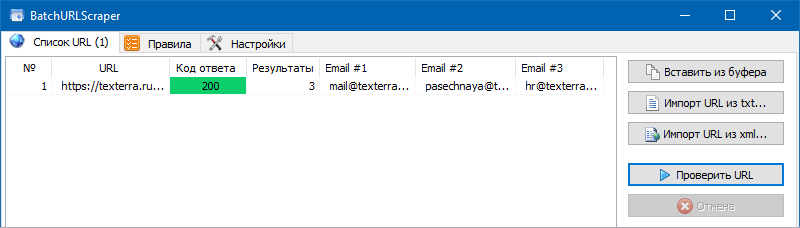
3. Извлечь контактный Email используя CSS.
Здесь совершенно все просто. Если на страничках веб-сайта встречаются гиперссылки вида "mailto:", то из их можно извлечь все почтовые адреса.
Для этого мы добавляем новое правило, избираем в нем CSSPath, и в код правила извлечения данных вставляем правило a[href^="mailto:"].
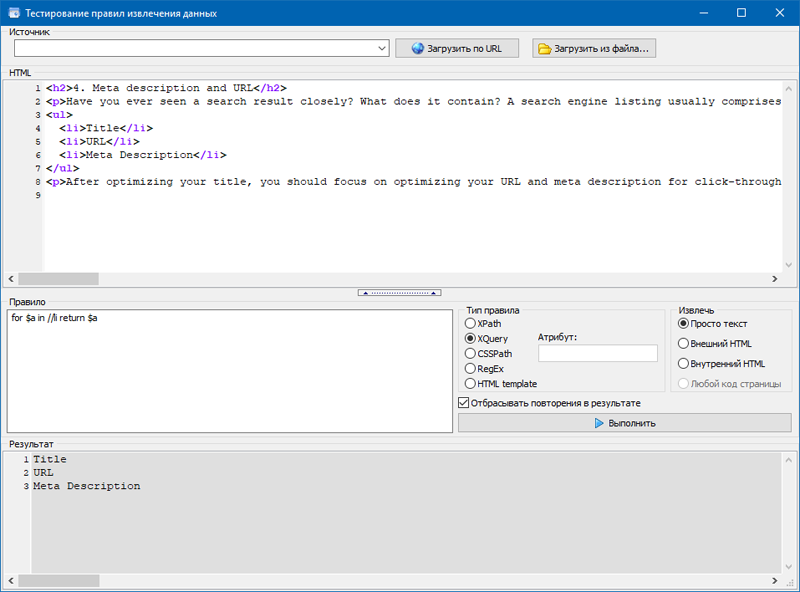
4. Извлечь значения в перечнях либо в таблице с помощью XQuery.
В отличии от остальных селекторов, XQuery дозволяет применять циклы и остальные способности языков программирования.
К примеру, с помощью оператора FOR можно получить значения всех списков LI. Пример:
Или выяснить, есть ли почта на страничках веб-сайта:
- if (count(//a[starts-with(@href, ‘mailto:’)])) then "Есть почта" else "Нет почты"
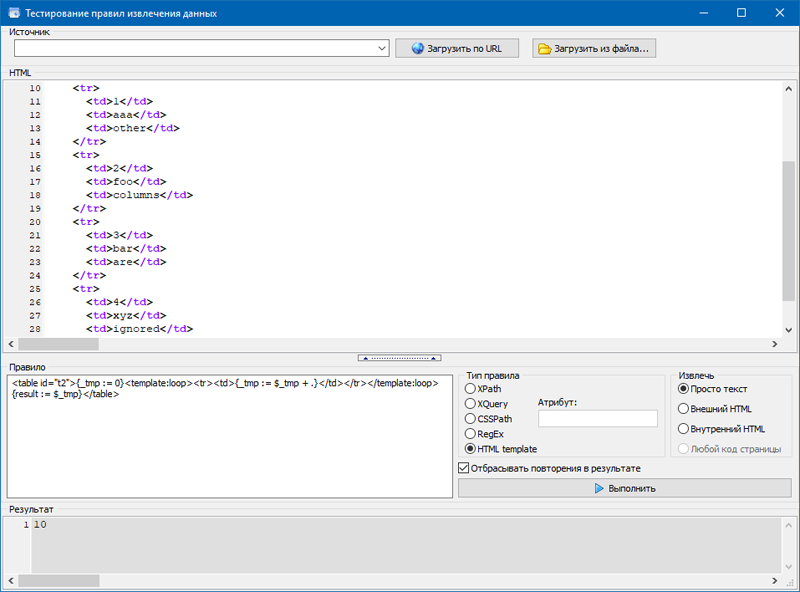
5. Внедрение HTML templates.
В данном языке извлечения данных в качестве функций можно применять XPath/XQuery, CSSpath, JSONiq и обыденные выражения.
1 aaa other 2 foo columns 3 bar are 4 xyz here К примеру, данный шаблон отыскивает таблицу с атрибутом и извлекает текст из второго столбца таблицы:
-
<table >Извлечение данных из 2-ой строчки:
-
<table >А этот темплейт вычисляет сумму чисел в колонке таблицы:
- <table := 0><template:loop><tr><td><_tmp := $_tmp + .></td></tr></template:loop>
</table>
Таковым образом, мы получили возможность извлекать фактически любые данные с интересующих страничек веб-сайтов, используя случайный перечень URL, включающий странички с различных доменов.
Ниже представлена таблица, с более нередко встречающимися правилами для извлечения данных.
Примеры кода для извлечения данных
В данной таблице мы собрали перечень более нередко встречающихся вариантов получения данных, которые можно извлечь используя разные типы экстракторов.
В которой компании заказать парсинг веб-сайтов
Мы, как компания, которая тоже занимается парсингом, имеем осознание о валютных и временных издержек на парсинг. Ну и нам тоже любопытно лучше ознакомиться с рынком и выяснить, какие цены выставляют клиентам остальные компании.
Все стараются представить свои способности «в наилучшем свете» и говорят о для себя мастерски и экспертно. Попробуем выяснить, так ли это по сути? Выясним, готовы ли компании взяться за парсинг объявлений Авито, на каких критериях и, самое увлекательное – за которую стоимость.
Почему мы избрали конкретно Авито? Поэтому что мы парсим Авито и отлично знакомы с их методами защиты. Как следует, можем отдать свою беспристрастную и осознанную оценку.
Мы выслали однообразное письмо в 36 веб-студий, деятельность которых прямо либо второстепенно связана с парсингом. Письмо имеет последующий текст:
Здрасти. Для нашего проекта нужен парсинг всех объектов недвижимости с Авито в Москве и Столичной области. Нам необходимы все общедоступные данные о недвижимости, включая телефон в текстовом формате. Частота обновления Excel-файла не пореже 1 раза в недельку. Готовы на длительную работу.
Вопросцы: Сколько это будет стоить? Сроки выполнения работ? Как вы работаете (ТЗ, контракт, предоплата, методы оплаты, разовая либо постоянная оплата (выдача денег по какому-нибудь обязательству))?
Мы выслали письма с лишь что сделанной электрической почты, проанализировали ответы и откоментировали их. Для всякого диалога у нас есть настоящая выгрузка переписок по email.
Необходимо отметить, что мы не желаем выставить какую-то компанию с худшей либо наилучшей стороны. Наша оценка полностью независима, даже не глядя на то, что все компании – наши соперники.
Какие выводы можно создать
При выбирании компании для заказа парсинга необходимо учесть огромное количество моментов: портфолио, сайт, экспертность, время на рынке и т.д. Общение с клиентом – это один из почти всех важных причин, от которых зависит итоговое решение клиента: закажет он услугу либо уйдет к иной компании.
С одной стороны, по одному только дискуссии задачки не совершенно верно судить о качестве предоставления услуг. А с иной, надежная команда мастерски подступает ко всем бизнес-процессам, как к конкретному выполнению услуги, так и к ее дискуссии с клиентом.
Результаты опроса
Сайт: vseprosite.ru
Стоимость: 6600 ₽
Наш комментарий: Тщательно описан весь процесс работы. Команда стремительно и понятно ответила на все поставленные вопросцы. Прислали пример файла парсинга, который должен получиться. Стоимость такового заказа очень низкая, что умопомрачительно. Возможно, в процессе выполнения услуги она будет изменена, потому что сбор такового размера инфы в сжатые сроки просит прокси-серверов, которые не упоминались в переписке. Без прокси можно уложиться в эту сумму, но из-за блокировок со стороны Авито парсер будет работать не наименее месяца и с внедрением безголового браузера. Общее воспоминание осталось не плохое.

Сайт: mrseo.su
Стоимость: 7000 ₽
Наш комментарий: Непременно, компания занимается парсингом, но, мы полагаем, что эта услуга не является главный и предлагается для наиболее обычных проектов. Нам понятно, с какими сложностями придется столкнуться при парсинге, потому считаем, что озвученная стоимость очень низкая. Может быть, ребята не парсили Авито ранее. Хотя они так и произнесли, что специализируются на SEO.
Сайт: site100.pro
Стоимость: 15 000 ₽ + ТЗ 4000 руб + прокси + сервер
Наш комментарий: Не плохая стоимость за парсинг, даже без учета издержек на прокси и аренду сервера. Но была выставлена полностью неадекватная стоимость за разработку технического задания. Не понятно, что может стоить 4000 ₽ в ТЗ? При общении пришлось растягивать ответы на любой вопросец. Показалось, что нет заинтригованности к клиенту и к заказу и, как следствие, ставится под сомнения свойство услуг. Воспоминание осталось негативное.
Сайт: xmldatafeed.com
Стоимость: 15 000 ₽
Наш комментарий: Предложили парсить по неплохой стоимости, но, к огорчению, не Авито, а ЦИАН, что весьма удивительно. Похоже, малая стоимость и резвые сроки выполнения обоснованы тем, что в компании уже есть выработки парсинга ЦИАНа и они готовы предоставить услуги с наименьшим желанием вовлекаться в работу, несмотря на потребности клиента. Знаем, что команда не плохая, но были огорчены сиим фактом. На все вопросцы были даны ответы в полной мере.
Сайт: parsing-service.ru
Стоимость: 10 000 ₽
Наш комментарий: Весьма малая стоимость, и это отлично. Но, к огорчению, нам произнесли, что таковой размер данных можно спарсить как минимум в месяц. Может быть, потому так недорого. Хотя мы успевали парсить за одну недельку. В целом воспоминание положительное.
Сайт: esk-solutions.com
Стоимость: 100–150 000 ₽ + аренда сервера 1710 ₽ + ?? ₽ прокси
Наш комментарий: Оперативно ответили на все вопросцы, ознакомили с ценами, сроками, критериями работы. Доп вопросцев не появлялось. Ребята молодцы, работают с клиентами продуктивно. Но считаем стоимость очень завышенной.
Сайт: agencyima.ru
Стоимость: 40–80 000 ₽
Наш комментарий: Ознакомили лишь с ценой. Остальную информацию прислали лишь при повторной просьбе, но ответили в полном объеме. Воспоминание осталось не плохое.
Сайт: rufago.ru
Стоимость: 100–220 000 ₽
Наш комментарий: Команда заинтересована в работе. Нас тщательно расспрашивали про данные, которые нам необходимы. Прислали пример для ознакомления, который должен получиться. Лишь в этом примере не были учтены наши пожелания по нужным полям, но, похоже, структура файла была бы скорректирована в процессе работы. Весьма отлично были описаны цены на все вероятные варианты работы. В этом отдаем подабающее. Но считаем, что стоимость очень высочайшая. Воспоминание осталось хорошее. Ребята молодцы.
Сайт: biznesup.com
Стоимость: 100 000 ₽
Наш комментарий: Был озвучен примерный бюджет и отлично описаны способы работы. Но большая часть наших вопросцев так и остались без ответа. Считаем, что компания, специализирующаяся на различных услугах, не заинтересована в парсинге сложных сайтов-доноров. Это, естественно, только мировоззрение, основанное на общении. Общее воспоминание – отрицательное.
Сайт: web2market.ru
Наш комментарий: В предоставлении услуг получили отказ в связи с отсутствием способности расшифровки номера телефона в текстовый формат. Хотя по сути существует огромное количество ПО (то есть программное обеспечение — комплект программ для компьютеров и вычислительных устройств) в вольном доступе, которое отлично совладевает с данной для нас задачей. Похоже тут услуга парсинга – это второстепенная деятельность, и компания практикуется на остальных услугах. Может быть, обычной парсинг был бы оказан.
Сайт: maurisweb.ru
Наш комментарий: Нашу заявку перенаправили в rufago. Данный сайт является партнером.
Сайт: yavorsky.ru
Наш комментарий: Отказали в услуге, но посоветовали xmldatafeed.
Сайт: soksaitov.ru
Наш комментарий: Отказались от работы.
Сайт: m-direct.ru
Наш комментарий: Отказались от работы.
Интернет-студии, которые нам так и не ответили
1-ые ответы мы получили практически через 10 минут опосля отправки заявок. Некие – спустя день. А последующие веб-студии не ответили совершенно (мы ожидали в течение 3-х дней).
- sparsim.org
- mgrab.ru
- sip-projects.com
- synweb.ru
- parser-saytov.ru
- parcingit.ru
- parserbot.ru
- kocherov.net
- webboss.pro
- iparser.ru
- parsing.center
- parser-na-zakaz.ru
- webteam.by
- seo2you.ru
- parserok.ru
- itweb-spb.ru
- parselab.org
- migulya.com
- index-soft.ru
- parsingdata.ru
- gagara-web.ru
- brawatch.ru
Резюме
Мы, к огорчению, получили всего 14 ответов от 36 компаний. Хотя ждали большего. Считаем, что заказать парсинг можно в 2–3 компаниях из всего перечня, которые озвучили приемлемую стоимость и при общении с которыми чувствовалась заинтригованность и профессионализм.
Кому-то эта статья станет точкой опоры при выбирании компании для заказа парсинга, а кому-то поможет просто сберечь время. Так либо по другому, наши комменты – это оценочное мировоззрение, основанное только на общении, потому решать для вас, какую компанию избрать.