Поиск по тексту в Word
Работа в редакторе текста Word подразумевает не только лишь печатание, да и внесение правок. Чтоб стремительно, например, отыскать и удалить текст, необходимо вызвать форму поиска. И записать в ней разыскиваемое слово. Как создать это в Ворде, на данный момент расскажу наиболее тщательно.
Где поиск в редакторе Word
Для того, чтоб раскрыть блок Отыскать, необходимо избрать вкладку Основная в панели редактора. Справа укажите поиск курсором мыши. 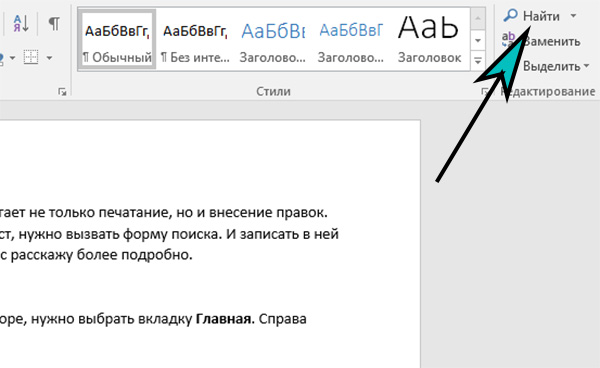 Жмем на пустую строчку и вводим слово, которое желаем отыскать. Если оно есть, то подсветится желтоватым цветом в теле документа.
Жмем на пустую строчку и вводим слово, которое желаем отыскать. Если оно есть, то подсветится желтоватым цветом в теле документа. 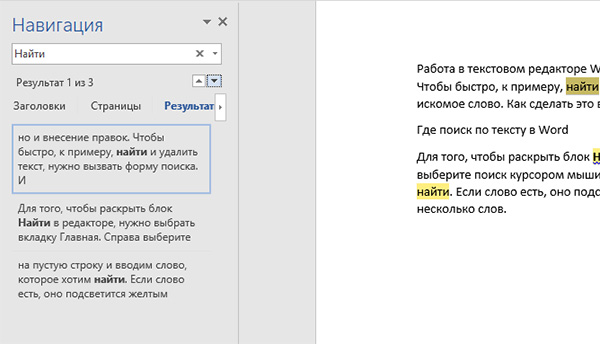 Находится обычно несколько слов. Сходу под строчкой для ввода размещены две мелкие стрелочки. С помощью их вы сможете передвигаться по схожим словам на страничке Word.
Находится обычно несколько слов. Сходу под строчкой для ввода размещены две мелкие стрелочки. С помощью их вы сможете передвигаться по схожим словам на страничке Word.
Чтоб находить на определённой страничке, изберите вкладку Странички и укажите её номер. Изберите Заголовок, если необходимо находить по этому типу текста. Будет работать, если документ «осознает», где они находятся. Иными словами, если они выделены как заглавия.
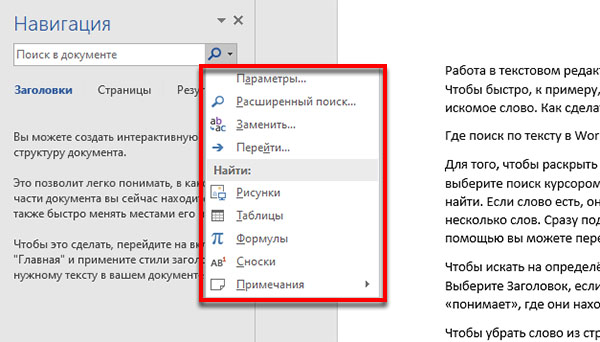
Чтоб убрать слово из строчки поиска, нажмите на крестик либо выделите и напишите новое. Чтоб избрать иной тип поиска, нажмите на лупу. В меню укажите что находить: таблицу, формулу, картинки либо сноски. Запирается окно поиска в Ворде крестиком в правом углу.
Жаркие клавиши вызова строчки поиска в Word
В почти всех компьютерных программках, позволяющих вводить текст, окно поиска по словам раскрывается композицией кнопок Ctrl + F. С помощью их можно стремительно вызывать строчку из хоть какого раздела редактора.
Назначить либо поглядеть имеющиеся жаркие клавиши в Ворде: вкладка Вставка -> Знаки -> Знак -> Остальные знаки. Поглядеть композиции можно во вкладке Особые знаки. Установить – по кнопочке Сочетание кнопок.
Отыскать и поменять в Word
Это довольно комфортная функция. С её помощью реально избежать мучительной рутинной работы с текстом. В одной строке мы пишем слово, которое необходимо отыскать, во 2-ой – слово, на которое его следует поменять. Вызвать окно для подмены можно последующим образом:
- Нажмите Ctrl + F – клавиши для открытия поиска.
- Избираем курсором иконку лупы.
- Указываем в контекстном меню пункт Поменять.

- Введите слова для поиска и подмены и нажмите Поменять все.
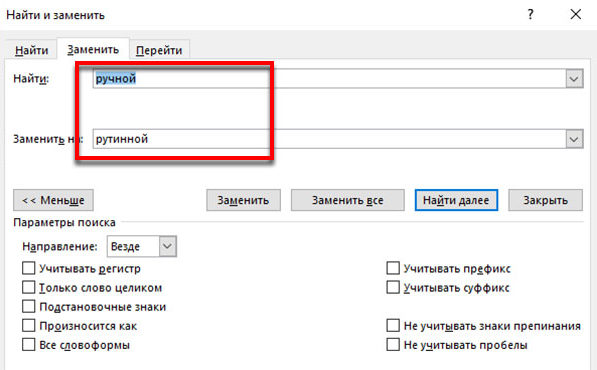
В извещении программка отчитается, сколько отыскала и сколько заменила слов. Сиим методом можно изменять наборы цифр – номера, даты, телефоны и т.д. Основная строчка поиска Ворд поддерживает ввод нескольких слов.
Поиск гиперссылок
В Word можно находить ссылки, в том числе сокрытые. Делается это последующим образом:
- Открываем раздел поиска и жмем на лупу в строке.
- Избираем Расширенный поиск.
- Понизу лицезреем клавишу Формат – жмем и находим Стиль.
- В перечне найдите пункт Ссылка.
- Жмем на клавишу Отыскать дальше.
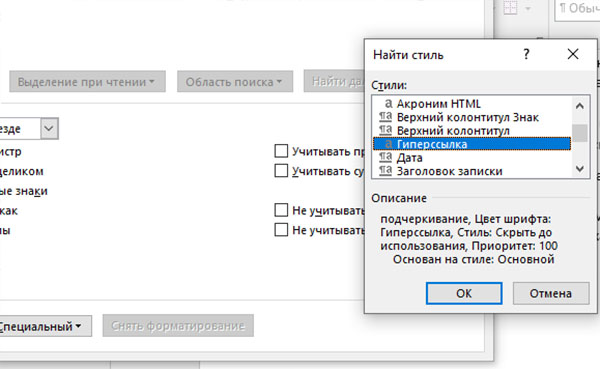
Ссылка будет подсвечена сероватым фоном, и вы можете от неё избавиться через контекстное меню. Нажмите ПКМ и изберите Удалить ссылку.
Отыскать дубли в документе
Время от времени приходится отыскивать и удалять однообразный текст в Word. Для этого можно использовать обыденную строчку для поиска, если слова-дубли либо числа известны. Еще сложней ситуация, когда предположительно схожие предложения есть и их необходимо отыскать. Если речь идёт о наборе цифровых данных, их можно экспортировать в Excel и стремительно найти при помощи функции поиска дублей.
Повторы в большенном тексте еще проще отыскать, разделив его на смысловые блоки. Например, для работы с 10 страничками текста идеальнее всего разбить его по 1 страничке. Специально для этого функции нет пока даже в новейшей версии редактора.
Находить слова и буковкы на другом языке в Word
Для того, чтоб создать текст неповторимым, юзеры время от времени добавляют в него схожие знаки из остальных языков. Вы сможете просто их отыскать.
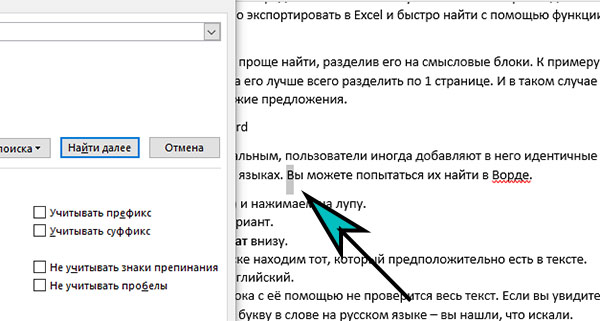
- Перебегаем в поиск (Ctrl + F) и жмем на лупу.
- Избираем расширенный вариант.
- Жмем на клавишу Формат понизу.
- И перебегаем в Язык. В перечне находим тот, который предположительно есть в тексте. Почаще всего употребляется британский.
- Жмем клавишу Отыскать дальше до того времени, пока с её помощью не проверится весь текст. Если вы увидите выделенную единственную буковку в слове на российском языке – вы отыскали, что находили.
Находить слова по тексту в Word можно на различных языках. Изберите заглавие из перечня. Отыскиваете российские знаки в тексте на британском.
Если материал был полезен, поделитесь им в соц сетях. Задавайте свои вопросцы в комментах. С радостью на их ответим.
Четыре метода отыскать дубликаты файлов в Windows.
Современный винчестер создается с впечатляющим объемом вольного места для хранения инфы. Но это не значит, что нет необходимости «хлопотать» о диске, освобождая его от мусора, дублированных файлов.
Создатель также советует:
Наличие файлов-дубликатов засоряет диск излишними записями инфы. Когда настанет время наращивать свободное место «замусоренных» дисков, на обнаружение дубликатов будет потрачено существенное время — ведь размер вашего винчестера весьма велик. Потому нахождение и удаление файлов-дубликатов необходимо создавать впору. Разглядим ряд приложений, умеющих находить такие файлы-дубликаты.
Содержание статьи
Total Commander
Первым приложением разглядим пользующийся популярностью Total Commander. Его многофункциональные способности широки, он также предоставляет инструмент для поиска файлов-дублей, расположенных в различных директориях вашего винчестера. Нужная нам операция доступна в общем поисковом модуле.

Вызов поискового модуля осуществляется при помощи жарких кнопок либо средством обычного перехода в основное меню, где пригодится избрать функцию «Поиск файлов». Вызов средством жарких кнопок делается методом одновременного нажатия композиции «Alt+F7».

Поисковый модуль дает целый ряд вкладок общих и продвинутых функций. Но сначало нам пригодится отобрать диск либо директорию, в которой нужно вести обнаружение. Это делается на вкладке общих характеристик. Потом, перейдем на вкладку «Добавочно».

В поисковом модуле откроем «Диски» и выберем диск «D».

Перейдем на вкладку «Добавочно».

В нижней части избранного раздела размещена функция нахождения файлов-дубликатов. Нам необходимо только настроить эту функцию, установив требуемые флажки напротив подходящих опций. К примеру, потому что показано на изображении ниже. В нашем случае поисковые деяния происходят на томе D.

Отысканные разыскиваемые дубликаты Total Commander располагает в небольшом окошке, в котором чуть что можно рассмотреть.

Нажав кнопку «Файлы на панель», отобразим их в главном окне. Сейчас, вы можете свободно удалять их, если убеждены, что такое действие не станет предпосылкой нестабильной работы программ и всей системы в целом.

Получаем итог в главном окне.

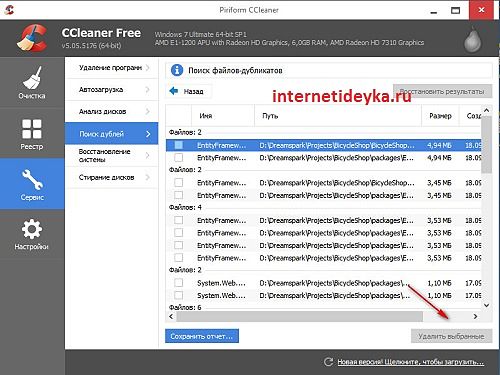
Отыскиваем дубликаты файлов в CCleaner
С недавнешних пор освеженный CCleaner также предоставляет функцию поиска дублирующихся файлов. Это приложение — обширно узнаваемый и пользующийся популярностью «уборщик» мусора на ПК (Персональный компьютер — компьютер, предназначенный для эксплуатации одним пользователем), потому присутствие в нем таковой функции полностью закономерно. Функцию «Поиск дублей» просто отыскать на вкладке «Сервис» программки.
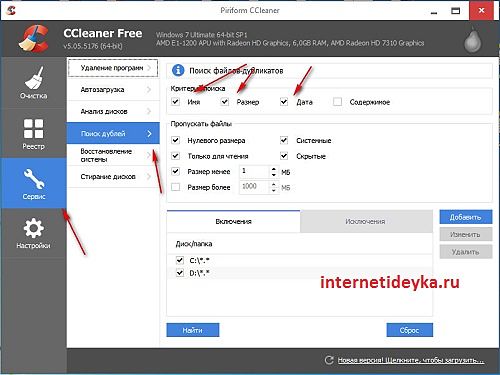
Обнаружение файлов-дубликатов CCleaner производит по нескольким характеристикам: имя, размер, дата, содержимое. Он также дает ряд нужных опций, которые разрешают пропустить либо добавить к нашей операции ряд особых файлов: сокрытые, системные, лишь для чтения, нулевого размера. Чтоб запустить поисковый модуль, довольно надавить кнопку «Отыскать».
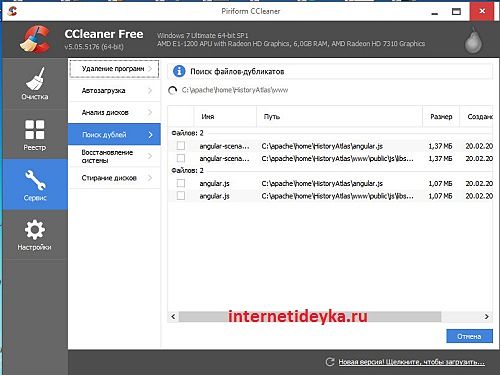
Опосля выполнения операции юзер имеет возможность избрать и удалить обнаруженные дубли.
SizeExplorer Pro
Данное приложение — мощнейший инструмент исследования томов диска и присоединенных дисковых устройств. Одной из его функций является поиск файлов-дубликатов.

Чтоб SizeExplorer сумел начать обнаружение дублей, поначалу необходимо проанализировать раздел, где нужно производить поиск.

Открывшееся меню предложит для вас целый ряд функций, посреди которых «Отыскать дубликаты». Нажатие данной функции дозволит открыть диалог с опциями опции поискового модуля.

Определимся с функциями обнаружения.

Произведем поиск дубликатов файлов по схеме размер-имя-содержимое. На обнаружение будет нужно некое время, но опосля окончания процесса в отдельном окошке мы увидим полный список дублей. При всем этом программка выдала нам огромное количество дублей неполного сходства, по определенному проценту сходства.

Результаты поисков схожих файлов:

Так можно избрать дубликаты:

Воспользуемся Ainvo Duplicate File Finder
В сети Веб доступна еще одна программка, представляющая энтузиазм для обнаружения дублирующихся файлов. Это Ainvo Duplicate File Finder. Это приложение обычное в использовании, так что им сумеет пользоваться даже не весьма опытнейший юзер компьютерных технологий. Чтоб пользоваться программкой, довольно надавить мышкой «Поиск схожих файлов».
Приложение сходу же начинает поиск, который продолжается довольно длительно, потому придется запастись терпением.

Поначалу происходит исследование дисков, потом приложение обрабатывает отысканный материал и лишь опосля этого происходит доборная обработка, результатом которой становится обнаружение файлов-дублей. Чтоб узреть отысканные дубликаты, пригодится открыть окошко «Схожие файлы».

Дальше, начинается поиск дублей.

Как лицезреем, в настройках выбрано два раздела для воплощения операции.

Мастер Аинво окончил выполнение операции — сейчас мы сможем открыть окно с ссылками на дубликаты.

Как лицезреем, дублей много и программка сходу же выделяет повторяющиеся, по ее воззрению, файлики.

Выбрано 2137 дубликатов, которые можно удалить при помощи мастера. Также, есть возможность просмотреть отчет о дубликатах.

Отчет раскрывается в веб-браузере.

Твердый диск временами нуждается в профилактике. Одной из профилактических процедур является очистка томов от мусора, огромную долю которого составляют продублированные файлы. Чтоб найти файлы-дубликаты, размещающиеся в различных директориях, можно пользоваться особыми программками. Посреди более достойных приложений, умеющих обнаруживать дублирующиеся файлы, назовем: Total Commander, CCleaner, SizeExplorer Pro, Ainvo Duplicate File Finder.
Решение алгоритмических заморочек: Поиск циклических частей в массиве
Этот пост является частью серии статей о том, как решать алгоритмические препядствия. Из собственного опыта, я сообразил, что большая часть создателей просто пошагово расписывают решение препядствия. Отсутствие обобщённого представления о дилемме, не дозволяет осознать её и отыскать действенное решение. Исходя из этого осознания, цель данной серии: обрисовывать процессы рассуждений о том, как решать такие препядствия с нуля.
Неувязка
- Отыскать дубликат в массиве
Процесс решения задачки
Перед тем как вы увидите решение, давайте мало побеседуем о самой дилемме. У нас есть: массив n + 1 частей с целочисленными переменными в спектре от 1 до n .
К примеру: мас с ив из 5 integers предполагает, что любой элемент будет иметь значение от 1 до 4 (включительно). Это автоматом значит, что будет по последней мере один дубликат.
Единственное исключение — это массив размером 1. Это единственный вариант, когда мы получим -1.
Brute Force
Способ Brute Force можно воплотить 2-мя вложенными циклами:
O(n²) — временная сложность и O(1) — пространственная сложность.
Count Iterations
Иной подход, это иметь структуру данных, в которой можно перечитать количество итераций всякого элемента integer. Таковой способ подойдёт как для массивов, так и для хэш-таблиц.
Реализация на Java:
Значение индекса i представляет число итераций i+1 .
Временная сложность этого решения — O(n), да и пространственная — O(n), потому что нам требуется доборная структура.
Sorted Array
Если мы применяем способ упрощения, то можно попробовать отыскать решение с отсортированным массивом.
В этом случае, нам необходимо сопоставить любой элемент с его соседом справа.
Реализация на Java:
Пространственная сложность O(1), но временная O(n log(n)), потому что нам необходимо отсортировать коллекцию.
Sum of the Elements
Ещё один метод — это суммирование частей массива и их сопоставление при помощи 1 + 2 + … + n.
В этом примере мы можем достигнуть результата временной трудности O(n) и пространственной O(1). Тем не наименее, это решение работает лишь в случае, когда мы имеем один дубликат.
Таковой метод приведёт в тупик. Но время от времени, чтоб отыскать среднее решение, необходимо перепробовать всё.
Marker
Кое-что увлекательное стоит упомянуть. Мы разглядывали решения, не беря во внимание условия, что спектр значений integer быть может от 1 до n . Из-за этого приметного условия каждое значение имеет собственный свой, соответственный ему индекс в массиве.
Сущность этого решения в том, чтоб разглядывать данный массив как перечень связей. Другими словами значение индекса показывает на его содержание.
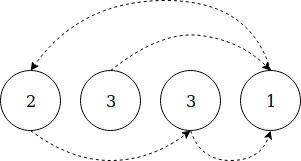
Мы проходим через любой элемент и помечаем соответственный индекс, прибавляя к нему символ минус. Элемент является дубликатом, если его индекс уже помечен минусом.
Давайте разглядим определенный пример, шаг за шагом:
Реализация на Java:
Это решение даёт итог временной трудности O(n) и пространственной O(1). Тем не наименее, будет нужно изменять перечень ввода.
Runner Technique
Есть ещё один метод, который подразумевает разглядывать массив как некоторый перечень связей (повторюсь, это может быть благодаря ограничению спектра значений частей).
Давайте проанализируем пример [1, 2, 3, 4, 2] :
Такое представление даёт нам осознать, что дубликат существует, когда есть цикл. Наиболее того, дубликат проявляется на точке входа цикла (в этом случае, 2-ой элемент).
Мы можем взять за базу метод нахождения цикла по Флойду, тогда мы придём к последующему методу:
- Инициировать два указателя slow и fast
- С каждым шагом: slow сдвигается на шаг со значением slow = a[slow] , fast сдвигается на два шага со значением fast = a[a[fast]]
- Когда slow == fast ― мы в цикле.
Можно ли считать этот метод завершённым? Пока нет. Точка входа этого цикла будет обозначать дубликат. Нам необходимо сбросить slow и двигать указатели шаг за шагом, пока они опять не станут равны.
Вероятная реализация на Java:
Это решение даёт итог временной трудности O(n) и пространственной O(1) и не просит конфигурации входящего перечня.
Как отыскать и удалить дубли страничек на веб-сайте? {Инструкция}
Дубли — это странички с схожим содержимым, т.е. они дублируют друг дружку.
Предпосылки, по которым странички дублируются, могут быть различными:
- автоматическая генерация;
- ошибки в структуре веб-сайта;
- неправильная разбивка 1-го кластера на две странички и остальные.
Дубли страничек — это плохо для продвижения и раскрутки веб-сайта, даже невзирая на то, что они могут появляться по естественным причинам. Дело в том, что поисковые боты ужаснее ранжируют странички, контент которых не много чем различается от остальных страничек. И чем больше таковых страничек, тем больше сигналов поисковым ботам, что это веб-сайт не достоин быть в топе выдачи.
Что происходит с веб-сайтом, у которого есть дубликаты страничек?
- Понижается его релевантность. Обе странички с схожим контентом пессимизируются в выдаче, теряют позиции и трафик.
- Понижается процент уникальности текстового контента. Из-за этого понизится неповторимость всего веб-сайта.
- Понижается вес URL-адресов веб-сайта. По любому запросу в выдачу поиска попадает лишь одна страничка, а если таковых схожих страничек несколько, все теряют в весе.
- Возрастает время на индексацию. Чем больше страничек, тем больше времени необходимо боту, чтоб регистрировать ваш веб-сайт. Для больших веб-сайтов препядствия с индексацией могут очень сказаться на трафике из поиска.
- Бан от поисковых машин. Можно совершенно вылететь из выдачи на неопределенный срок.
В общем, становится ясно, что дубли никому не необходимы. Давайте разбираться, как отыскать и обезвредить дублирующиеся странички на веб-сайте.
Как отыскать дубли страничек?

Кирилл Бузаков,
SEO-оптимизатор компании SEO.RU:
«Когда мы получаем в работу веб-сайт, мы проверяем его на наличие дублей страничек, отдающих код 200. Разберем, какие это могут быть дубли.
Вероятные типы дублей страничек на веб-сайте
Дубли страничек с протоколами http и https.
К примеру: https://site.ru и http://site.ru
Дубли с www и без.
К примеру: https://site.ru и https://www.site.ru
Дубли со слешем на конце URL и без.
К примеру: https://site.ru/example/ и https://site.ru/example
Дубли с множественными слешами в середине или в конце URL.
Строчные и строчные буковкы на разных уровнях вложенности в URL.
К примеру: https://site.ru/example/ и https://site.ru/EXAMPLE/
Дубли с добавлением на конце URL:
- index.php;
- home.php;
- index.html;
- home.html;
- index.htm;
- home.htm.
К примеру: https://site.ru/example/ и https://site.ru/example/index.html
Дубли с добавлением случайных знаков или в качестве новейшего уровня вложенности (в конце либо середине URL), или в имеющиеся уровни вложенности.
К примеру: https://site.ru/example/saf3qA/, https://site.ru/saf3qA/example/ и https://site.ru/examplesaf3qA/
Добавление случайных цифр в конце URL в качестве новейшего уровня вложенности.
К примеру: https://site.ru/example/ и https://site.ru/example/32425/
Дубли с добавлением «звездочки» в конце URL.
К примеру: https://site.ru/example/ и https://site.ru/example/*
Дубли с подменой дефиса на нижнее подчеркивание либо напротив.
К примеру: https://site.ru/defis-ili-nizhnee-podchyorkivanie/ и https://site.ru/defis_ili_nizhnee_podchyorkivanie/
Дубли с неправильно обозначенными уровнями вложенности.
К примеру: https://site.ru/category/example/ и https://site.ru/example/category/
Дубли с отсутствующими уровнями вложенности.
К примеру: https://site.ru/category/example/ и https://site.ru/example/
Как найти дубли страничек?
Поиск дублей страничек можно произвести различными методами. Если вы желаете собрать все-все дубли и ничего не упустить, лучше применять все нижеперечисленные сервисы вместе. Но для поиска главных довольно какого-то 1-го инструмента, выбирайте, какой для вас поближе и удобнее.
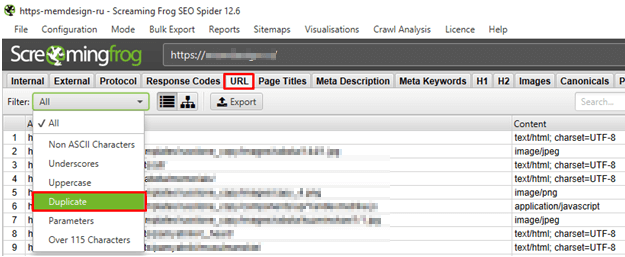
Парсинг веб-сайта в спец программке
Для поиска дубликатов подступает программка Screaming Frog SEO Spider. Запускаем сканирование, а опосля него проверяем дубли в директории URL → Duplicate:
Не считая того, в директории Protocol → HTTP проверяем странички с протоколом http — есть ли посреди их те, у каких Status Code равен 200:
Онлайн-сервисы.
1-ый, пригодный нашим целям сервис, — это ApollonGuru.
- Избираем 5-7 типовых страничек веб-сайта. К примеру, набор быть может таковым: основная, разводящая, карточка продукта/страничка услуги, статья в блоге, также остальные принципиальные странички в зависимости от типа веб-сайта.
- Вносим их в поле «Поиск дублей страничек» и жмем клавишу «Выслать»:
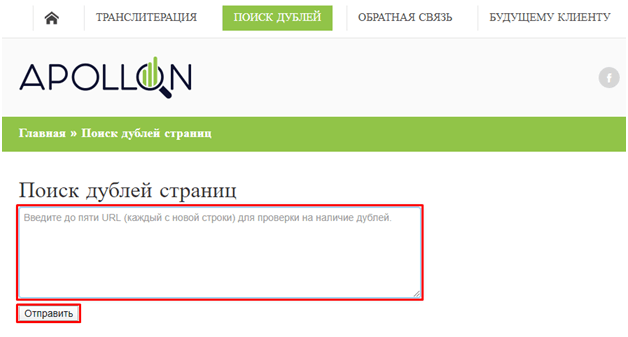
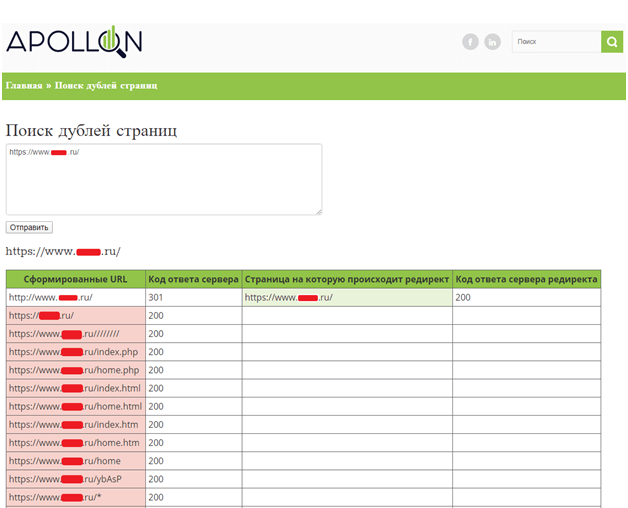
Не считая того, нужно инспектировать, что с дублей настроены прямые 301 редиректы на главные версии этих же страничек.
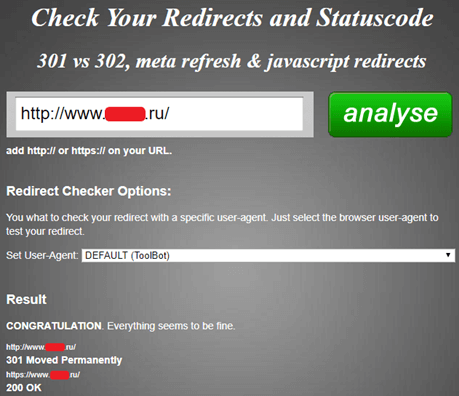
Также проверка дублей веб-сайта вероятна онлайн-сервисом Check Your Redirects and Statuscode, но он подступает лишь в том случае, если необходимо проанализировать один URL-адрес:
Панели вебмастеров Yandex’а и Гугл.
Отыскать дублирующиеся странички можно при помощи собственных инструментов поисковиков — Yandex.Веб-мастера и Гугл Search Console.
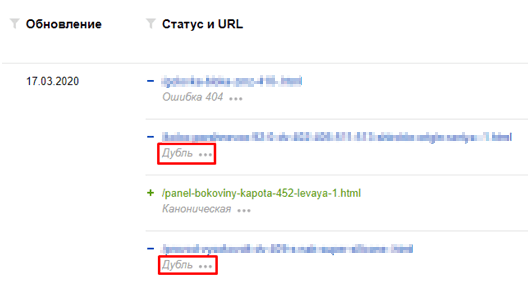
В Yandex.Веб-мастере анализируем раздел «Индексирование», дальше — «Странички в поиске»:
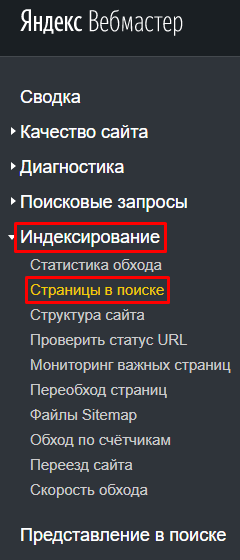
Там можно узреть текущую индексацию веб-сайта и разыскиваемые дубли страничек:
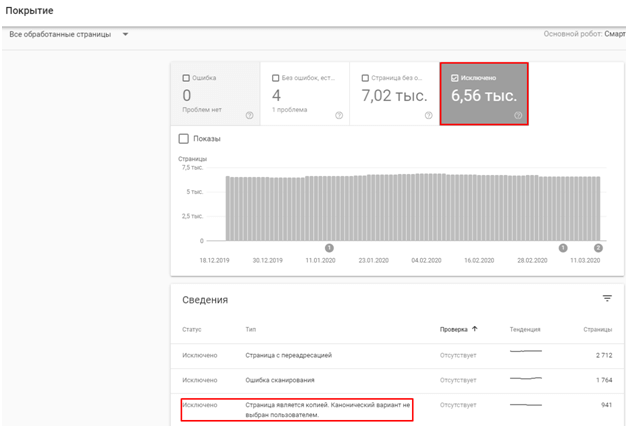
В Search Console анализируем раздел «Покрытие», а конкретно пункт с исключенными из индекса страничками:
Собираем все дубли в одну таблицу либо документ. Потом отправляем их в работу программеру:
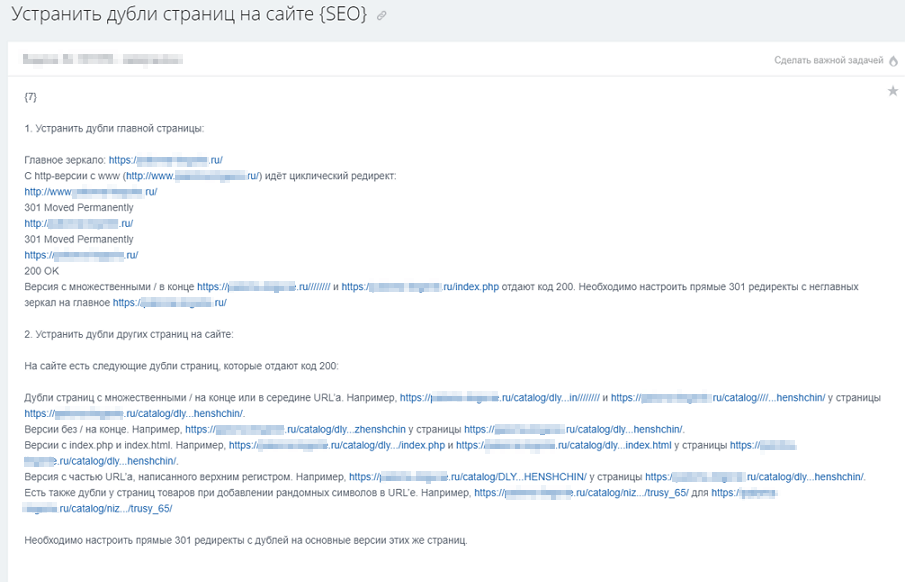
Пытайтесь подробнее разъяснить программеру задачку, потому что адресов быть может много».
Как убрать дубли страничек на веб-сайте?

Евгений Костырев,
веб-программист компании SEO.RU:
«С дублирующимися страничками биться можно различными методами. Если есть возможность, стоит применять ручной способ. Но таковая возможность есть не постоянно, поэтому что тут необходимы суровые способности программирования: как минимум, необходимо отлично разбираться в особенностях CMS собственного веб-сайта.
Остальные же способы не требуют специализированных познаний и тоже могут отдать неплохой итог. Давайте разберем их.
301 редирект
301 редирект — это самый надежный метод избавления от дублей, но при всем этом самый требовательный к проф способностям программера.
Как это работает: если веб-сайт употребляет сервер Apache, то нужные правила в файле .htaccess при помощи постоянных выражений.
Самый обычной вариант 301 редиректа с одной странички на другую:
Redirect 301 /test-1/ http://site.ru/test-2/
Устанавливаем 301 редирект со странички с www на страничку без www (основное зеркало — домен без www):
Организуем редирект с протокола http на https:
Прописываем 301 редирект для index.php, index.html либо index.htm (к примеру, в Joomla), массовая {склейка}:
RewriteCond %
RewriteRule^(.*)index.(php|html|htm)$ http://site.ru/$1 [R=301,L]
Если же веб-сайт употребляет Nginx, то правила прописываются в файле nginx.conf. Для перенаправления также необходимо прописывать правила при помощи постоянных выражений, к примеру:
location = /index.html <
return 301 https://site.com
>
Заместо index.html можно указать хоть какой иной URL-адрес странички вашего веб-сайта, с которого необходимо создать редирект.
На этом шаге принципиально смотреть за правильностью новейшей части кода: если в ней будут ошибки, пропадут не только лишь дубли, да и совершенно весь веб-сайт из всего веба.
Создание канонической странички
Внедрение canonical показывает поисковому пауку на ту единственную страничку, которая является уникальной и обязана быть в поисковой выдаче.
Чтоб выделить такую страничку, необходимо на всех URL дублей прописать код с адресом уникальной странички:
В 1С-Битрикс это делается при помощи языка программирования PHP в соответственных файлах. Таковая же история и с CMS Joomla: без вмешательства программера либо собственных способностей программирования тут не обойтись.
Директива Disallow в robots.txt
В файле robots.txt содержатся аннотации для поисковых краулеров, как конкретно регистрировать веб-сайт.
Если на веб-сайте есть дубли, можно запретить краулеру их регистрировать при помощи директивы:
User-agent: *
Disallow: site.ru/contacts.php?work=225&s=1
Таковой метод фактически не просит способностей программера, но он не подступает, если дублей много: весьма много времени уйдет на изменение robots.txt всякого дубля».
Выбирайте метод, исходя из собственных способностей программирования и личных предпочтений, и не давайте поисковикам повод колебаться в релевантности и качестве вашего веб-сайта.