Поиск и подсчет самых нередких значений
Необходимость поиска больших и меньших значений в любом бизнесе явна: самые выгодные продукты либо ценные клиенты, самые большие поставки либо партии и т.д.
Но вровень с сиим, время от времени приходится находить в данных не лучшие, а самые нередко встречающиеся значения, что хоть и звучит похоже, но, по факту, совершенно не то же самое. Применительно к магазину, к примеру, это быть может поиск не самых выгодных, а самых нередко покупаемых продуктов либо самое нередко встречающееся количество позиций в заказе, минут в общении и т.п.
В таковой ситуации задачку придется решать незначительно по-разному, зависимо от того, с чем мы имеем дело — с числами либо с текстом.
Поиск самых нередко встречающихся чисел
Представим, перед нами стоит задачка проанализировать имеющиеся данные по продажам в магазине, с целью найти более нередко встречающееся количество приобретенных продуктов. Для определения самого нередко встречающегося числа в спектре можно употреблять функцию МОДА (MODE) :
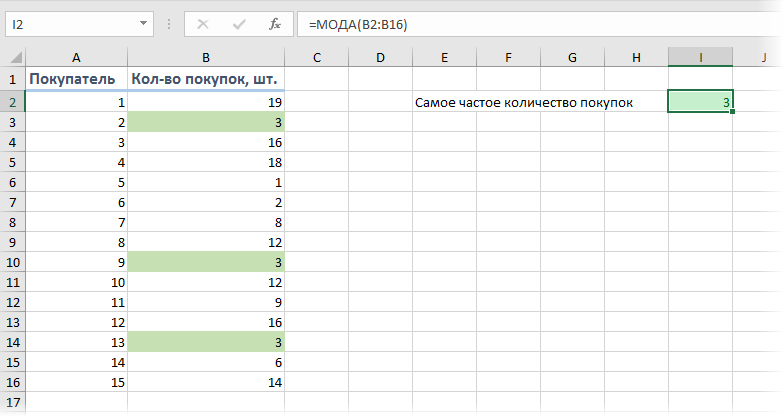
Т.е., согласно нашей статистике, почаще всего покупатели получают 3 шт. продукта.
Если существует не одно, а сходу несколько значений, встречающихся идиентично наибольшее количество раз (несколько мод), то для их выявления можно употреблять функцию МОДА.НСК (MODE.MULT) . Ее необходимо вводить как формулу массива, т.е. выделить сходу несколько пустых ячеек, чтоб хватило на все моды с припасом и ввести в строчку формул =МОДА.НСК(B2:B16) и надавить сочетание кнопок Ctrl+Shift+Enter.
На выходе мы получим перечень всех мод из наших данных:
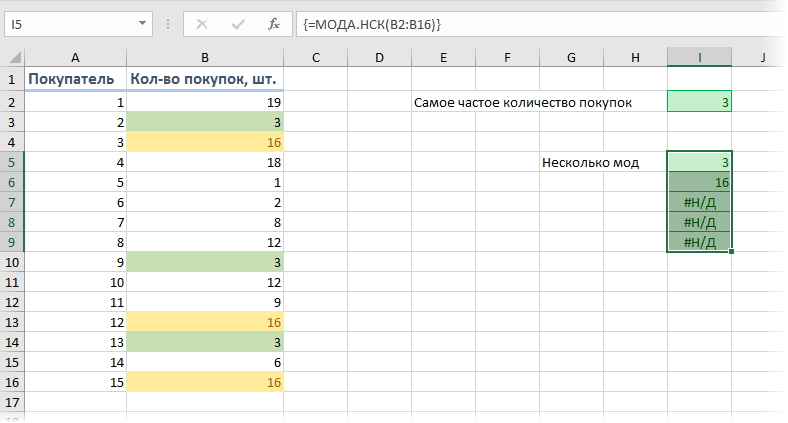
Т.е., судя по нашим данным, нередко берут не только лишь по 3, да и по 16 шт. продуктов. Направьте внимание, что в наших данных лишь две моды (3 и 16), потому другие ячейки, выделенные «про припас», будут с ошибкой #Н/Д.
Частотный анализ по спектрам функцией ЧАСТОТА
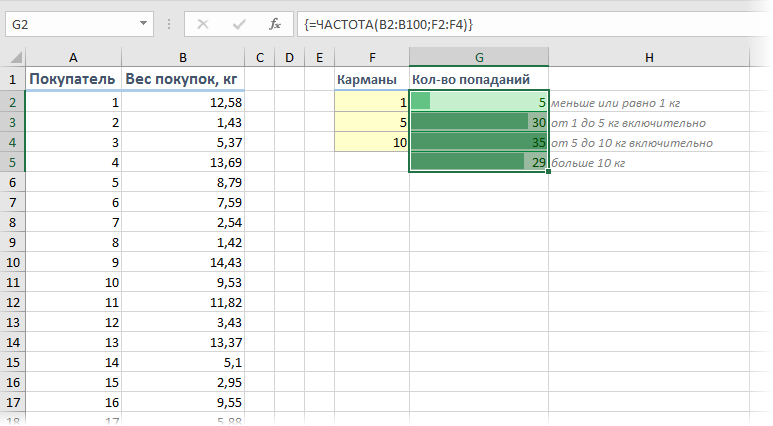
Если же необходимо проанализировать не целые, а дробные числа, то вернее будет оценивать не количество схожих значений, а попадание их в данные спектры. К примеру, нам нужно осознать какой вес почаще всего бывает у покупаемых продуктов, чтоб верно избрать для магазина телеги и упаковочные пакеты пригодного размера. Иными словами, нам необходимо найти сколько чисел попадает в интервал 1..5 кг, сколько в интервал 5..10 кг и т.д.
Для решения схожей задачки можно пользоваться функцией ЧАСТОТА (FREQUENCY) . Для нее необходимо заблаговременно приготовить ячейки с интересующими нас интервалами (кармашками) и потом выделить пустой спектр ячеек (G2:G5) по размеру на одну ячейку больший, чем спектр кармашков (F2:F4) и ввести ее как формулу массива, нажав в конце сочетание Ctrl+Shift+Enter:
Частотный анализ сводной таблицей с группировкой
Другой вариант решения задачки: сделать сводную таблицу, где поместить вес покупок в область строк, а количество покупателей в область значений, а позже применить группировку — щелкнуть правой клавишей мыши по значениям весов и избрать команду Группировать (Group) . В показавшемся окне можно задать пределы и шаг группировки:
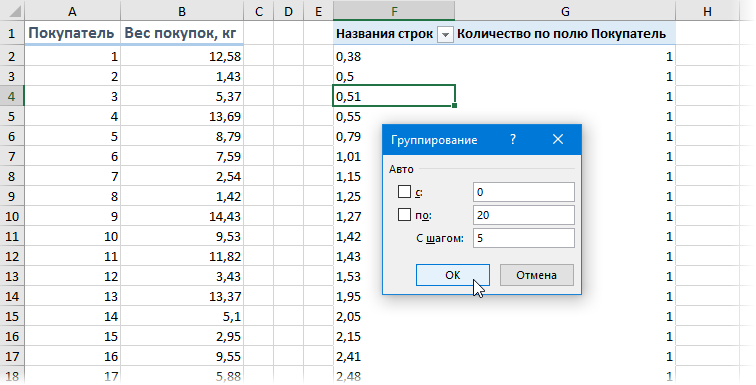
. и опосля нажатия на клавишу ОК получить таблицу с подсчетом количества попаданий покупателей в любой спектр группировки:
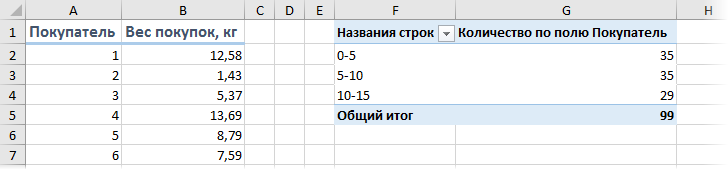
Минусы такового метода:
- шаг группировки быть может лишь неизменным, в отличие от функции ЧАСТОТА, где кармашки можно задать полностью любые
- сводную таблицу необходимо обновлять при изменении начальных данных (щелчком правой клавиши мыши — Обновить), а функция пересчитывается автоматом «на лету»
Поиск самого нередко встречающегося текста
Если мы имеем дело не с числами, а с текстом, то подход к решению будет принципно иной. Представим, что у нас есть таблица из 100 строк с данными о проданных в магазине товарах, и нам необходимо найти, какие продукты покупались более нередко?
Самым обычным и естественным решением будет добавить рядом столбец с функцией СЧЁТЕСЛИ (COUNTIF) , чтоб подсчитать количество вхождений всякого продукта в столбце А:
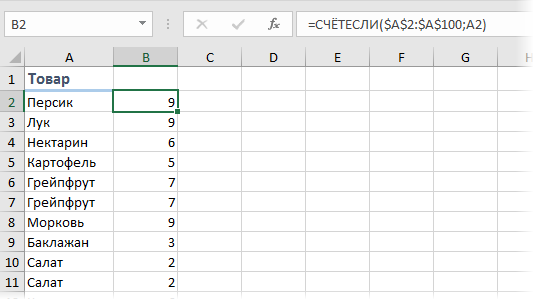
Потом, само-собой, отсортировать получившийся столбец по убыванию и поглядеть на 1-ые строки.
Либо же добавить к начальному списку столбец с единичками и выстроить по получившейся таблице сводную, подсчитав суммарное количество единичек для всякого продукта:
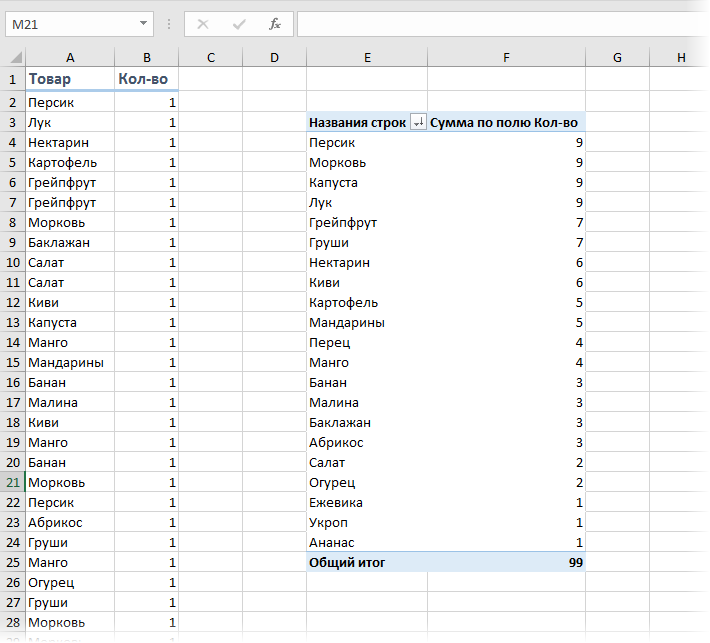
Если начальных данных не весьма много и принципно не охото воспользоваться сводными таблицами, то можно употреблять формулу массива:
10 фаворитных статистических функций в Microsoft Excel

Статистическая обработка данных – это сбор, упорядочивание, обобщение и анализ инфы с возможностью определения тенденции и прогноза по изучаемому явлению. В Excel есть большущее количество инструментов, которые помогают проводить исследования в данной области. Крайние версии данной нам программки в плане способностей фактически ничем не уступают спец приложениям в области статистики. Главными инструментами для выполнения расчетов и анализа являются функции. Давайте изучим общие индивидуальности работы с ними, также подробнее остановимся на отдельных более нужных инструментах.
Статистические функции
Как и любые остальные функции в Экселе, статистические функции оперируют аргументами, которые могут иметь вид неизменных чисел, ссылок на ячейки либо массивы.
Выражения можно вводить вручную в определенную ячейку либо в строчку формул, если отлично знать синтаксис определенного из их. Но намного удобнее пользоваться особым окном аргументов, которое содержит подсказки и уже готовые поля для ввода данных. Перейти в окно аргумента статистических выражений можно через «Мастер функций» либо при помощи клавиш «Библиотеки функций» на ленте.
Запустить Мастер функций можно 3-мя методами:
-
Кликнуть по пиктограмме «Вставить функцию» слева от строчки формул.

При выполнении хоть какого из перечисленных выше вариантов раскроется окно «Мастера функций».
Потом необходимо кликнуть по полю «Категория» и избрать значение «Статистические».

Опосля этого раскроется перечень статистических выражений. Всего их насчитывается наиболее сотки. Чтоб перейти в окно аргументов хоть какого из их, необходимо просто выделить его и надавить на клавишу «OK».

Для того, чтоб перейти к необходимым нам элементам через ленту, перемещаемся во вкладку «Формулы». В группе инструментов на ленте «Библиотека функций» кликаем по кнопочке «Остальные функции». В открывшемся перечне избираем категорию «Статистические». Раскроется список доступных частей подходящей нам направленности. Для перехода в окно аргументов довольно кликнуть по одному из их.

Оператор МАКС предназначен для определения наибольшего числа из подборки. Он имеет последующий синтаксис:

В поля аргументов необходимо ввести спектры ячеек, в каких находится числовой ряд. Наибольшее число из него эта формула выводит в ту ячейку, в какой находится сама.
По наименованию функции МИН понятно, что её задачки прямо обратны предшествующей формуле – она отыскивает из огромного количества чисел меньшее и выводит его в заданную ячейку. Имеет таковой синтаксис:
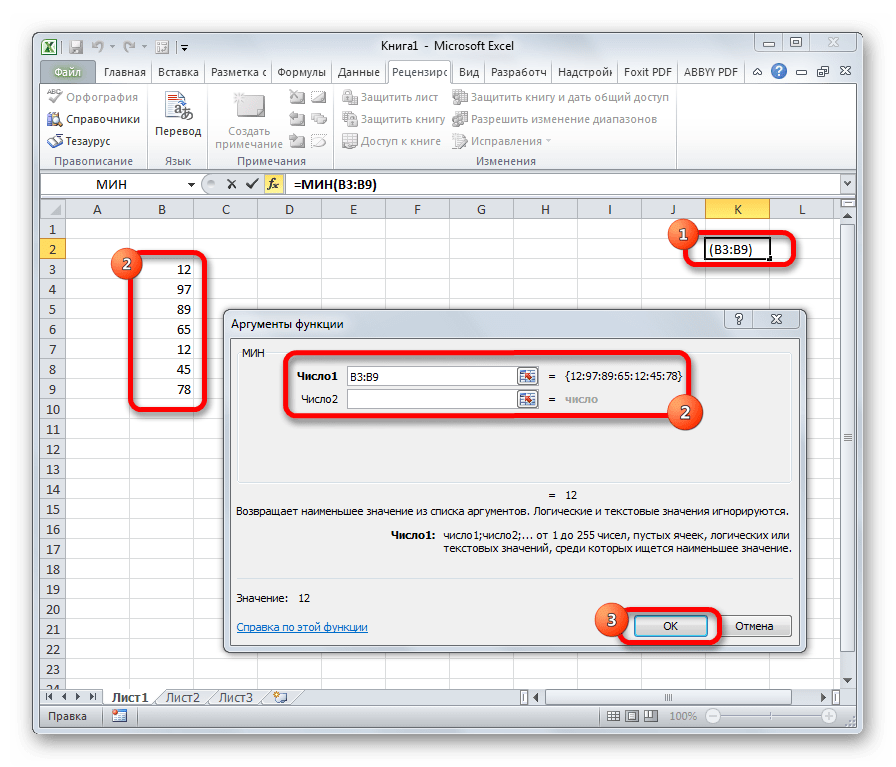
СРЗНАЧ
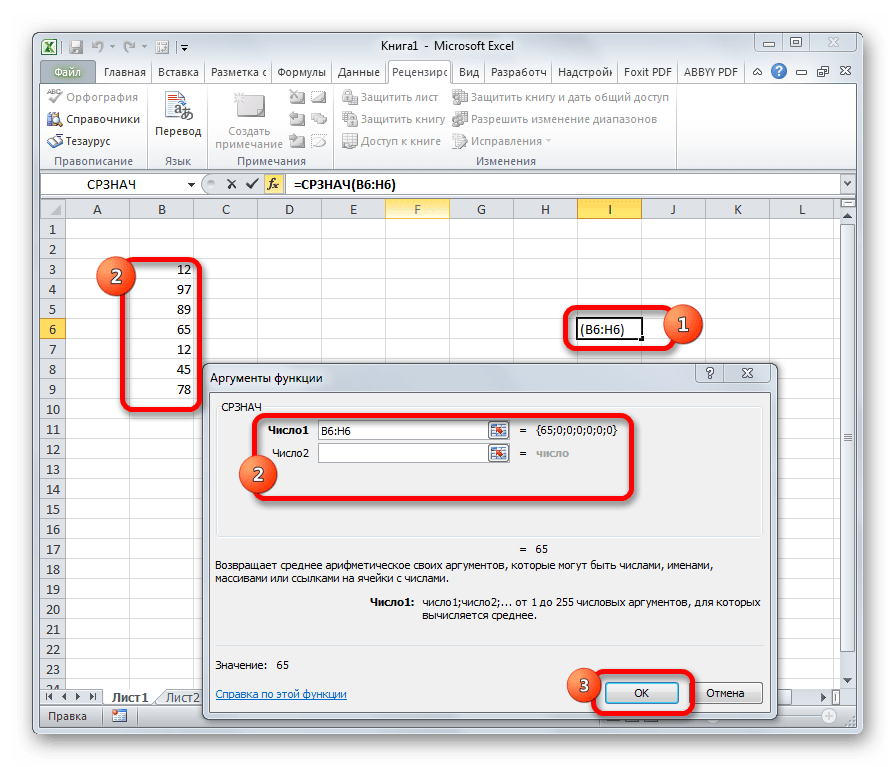
Функция СРЗНАЧ отыскивает число в обозначенном спектре, которое поближе всего находится к среднему арифметическому значению. Итог этого расчета выводится в отдельную ячейку, в какой и содержится формула. Шаблон у неё последующий:
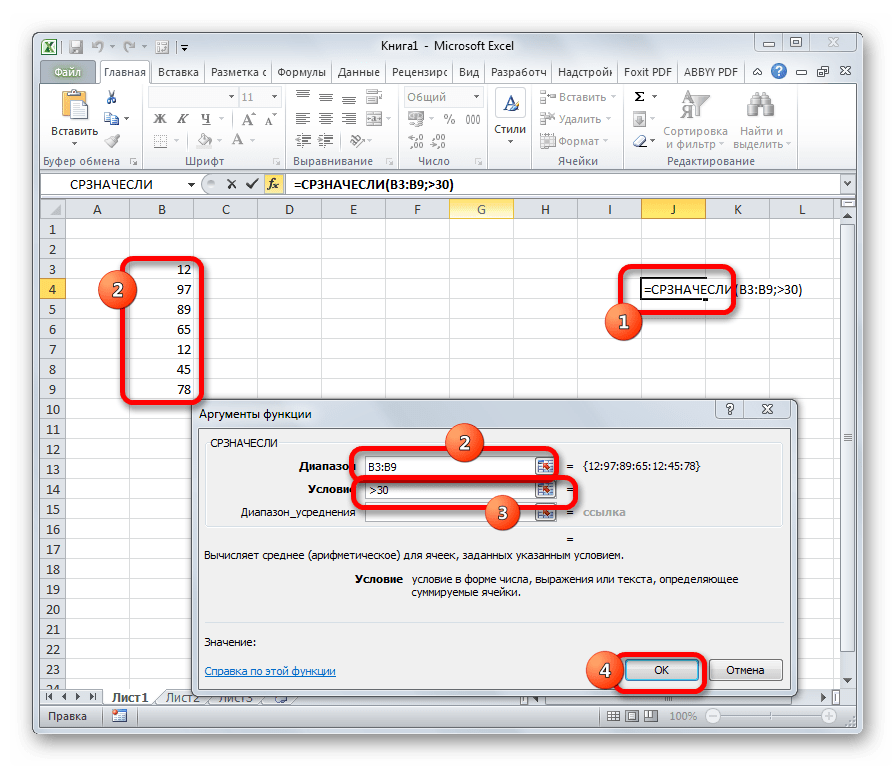
СРЗНАЧЕСЛИ
Функция СРЗНАЧЕСЛИ имеет те же задачки, что и предшествующая, но в ней существует возможность задать доп условие. К примеру, больше, меньше, не равно определенному числу. Оно задается в отдельном поле для аргумента. Не считая того, в качестве необязательного аргумента быть может добавлен спектр усреднения. Синтаксис последующий:
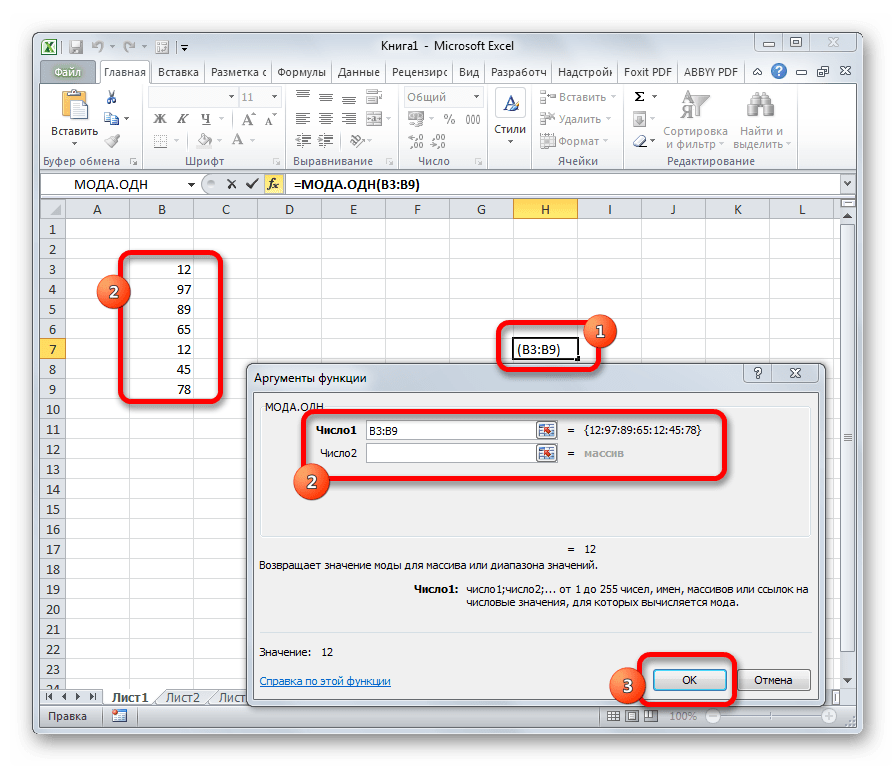
МОДА.ОДН
Формула МОДА.ОДН выводит в ячейку то число из набора, которое встречается почаще всего. В старенькых версиях Эксель была функция МОДА, но в наиболее поздних она была разбита на две: МОДА.ОДН (для отдельных чисел) и МОДА.НСК(для массивов). Вообщем, старенькый вариант тоже остался в отдельной группе, в какой собраны элементы из прошедших версий программки для обеспечения сопоставимости документов.
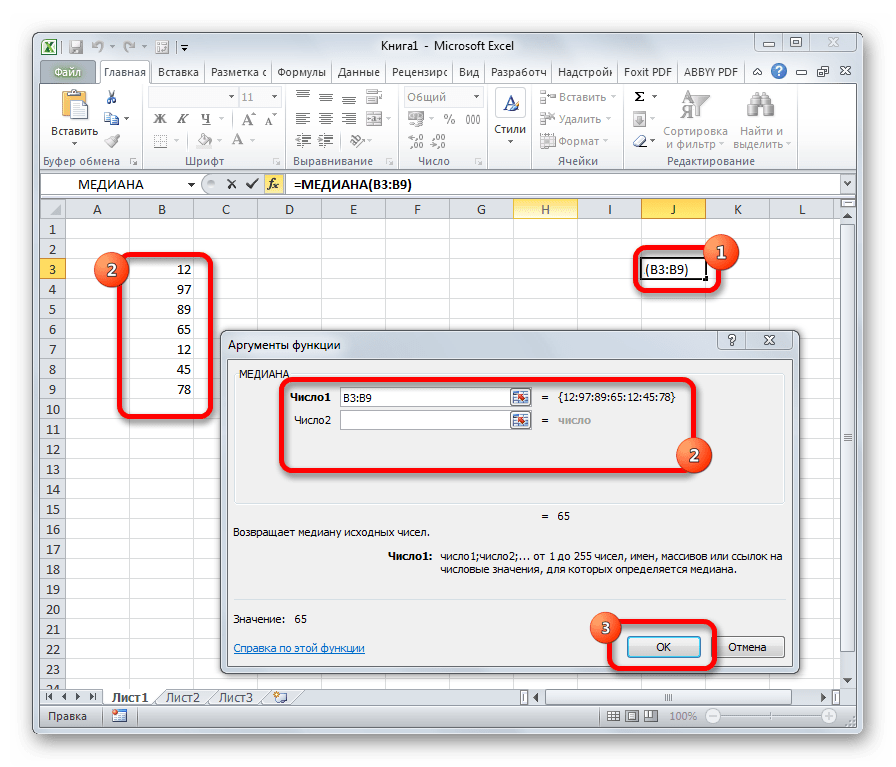
МЕДИАНА
Оператор МЕДИАНА описывает среднее значение в спектре чисел. Другими словами, устанавливает не среднее арифметическое, а просто среднюю величину меж большим и минимальным числом области значений. Синтаксис смотрится так:
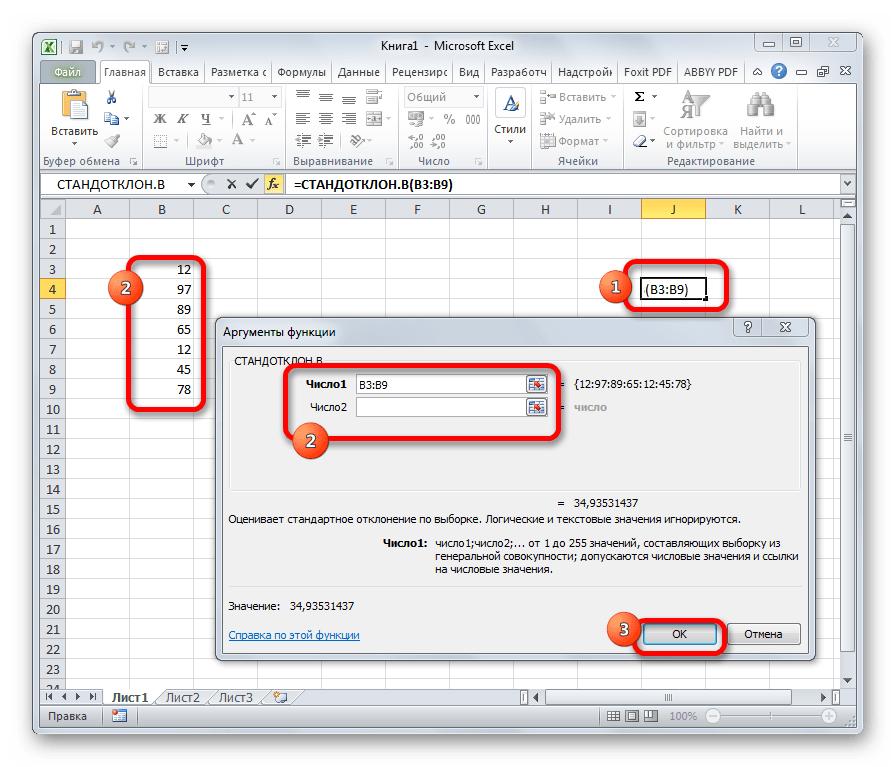
СТАНДОТКЛОН
Формула СТАНДОТКЛОН так же, как и МОДА является пережитком старенькых версий программки. На данный момент употребляются современные её подвиды – СТАНДОТКЛОН.В и СТАНДОТКЛОН.Г. 1-ая из их создана для вычисления обычного отличия подборки, а 2-ая – генеральной совокупы. Данные функции употребляются также для расчета среднего квадратичного отличия. Синтаксис их последующий:
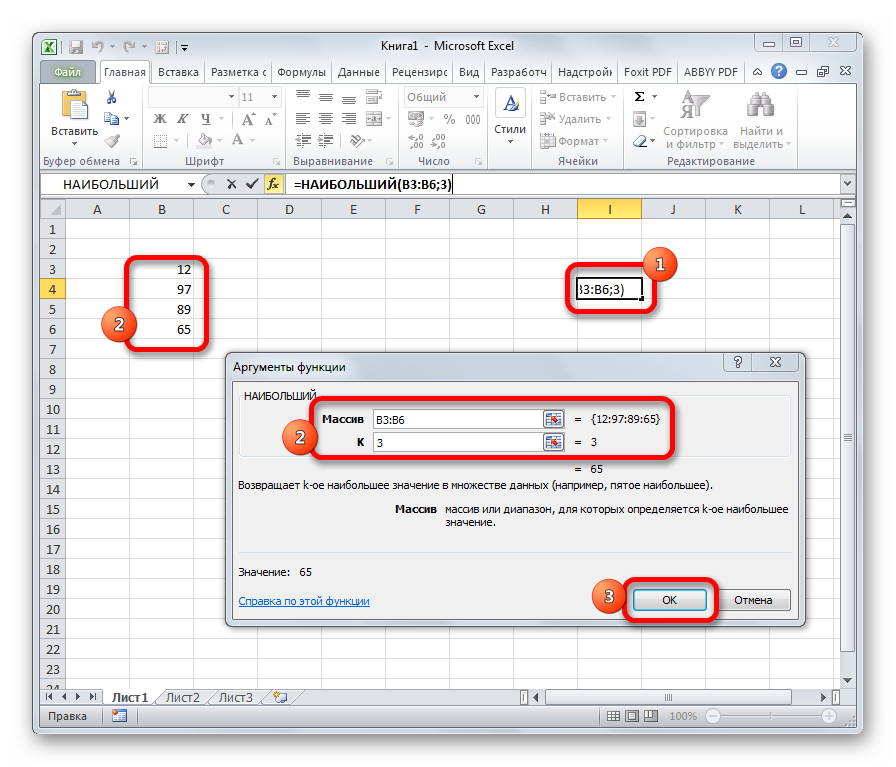
НАИБОЛЬШИЙ
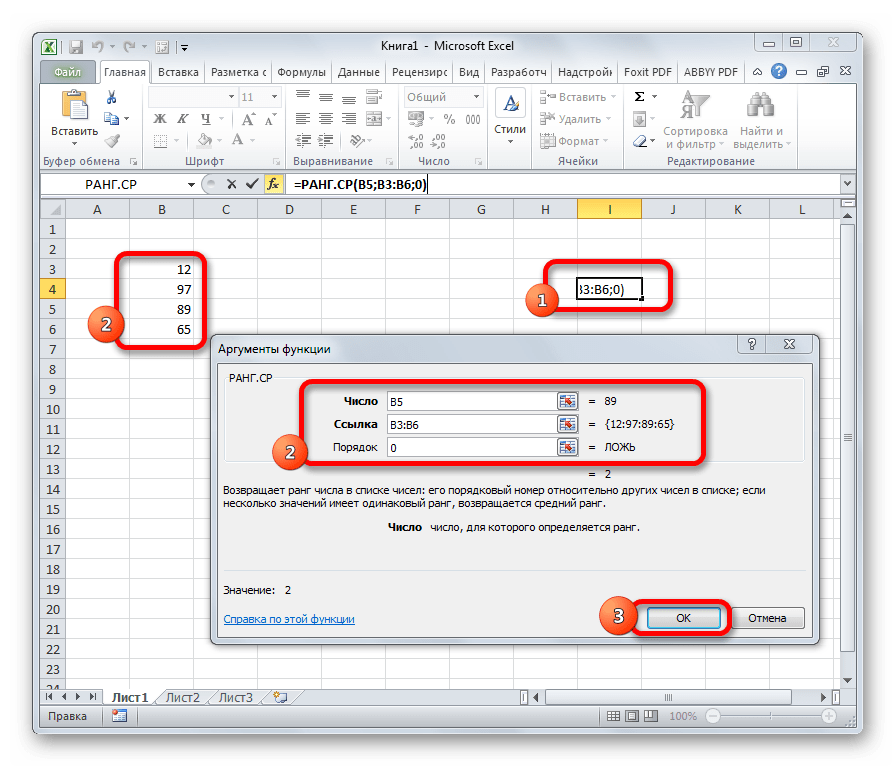
Данный оператор указывает в избранной ячейке обозначенное в порядке убывания число из совокупы. Другими словами, если мы имеем совокупа 12,97,89,65, а аргументом позиции укажем 3, то функция в ячейку возвратит третье по величине число. В данном случае, это 65. Синтаксис оператора таковой:
В данном случае, k — это порядковый номер величины.
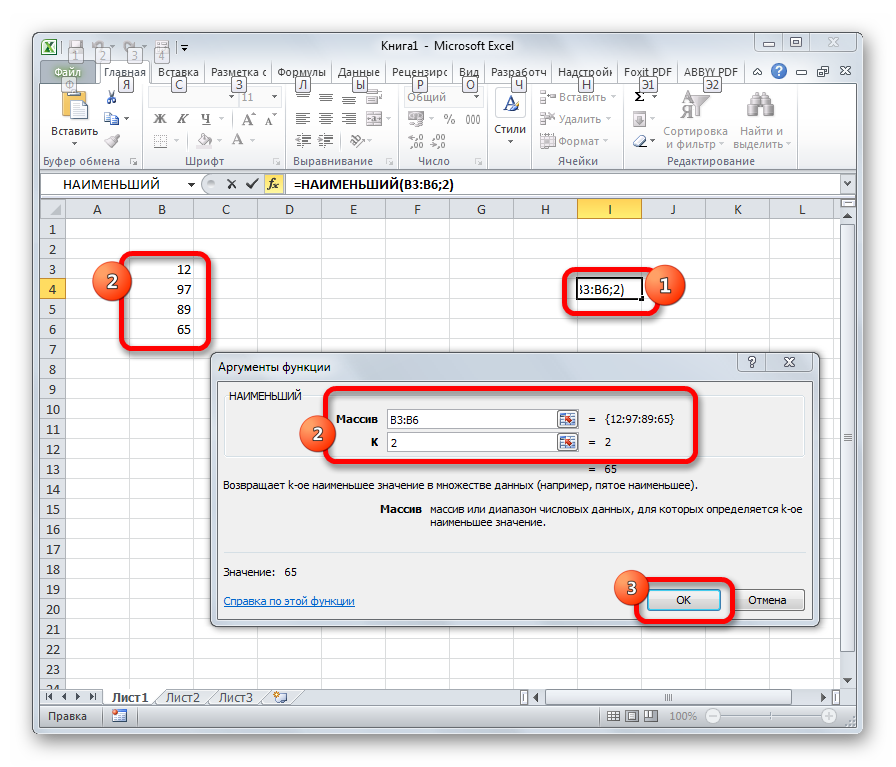
НАИМЕНЬШИЙ
Данная функция является зеркальным отражением предшествующего оператора. В ней также вторым аргументом является порядковый номер числа. Вот лишь в этом случае порядок считается от наименьшего. Синтаксис таковой:
РАНГ.СР
Эта функция имеет действие, оборотное предшествующим. В обозначенную ячейку она выдает порядковый номер определенного числа в выборке по условию, которое обозначено в отдельном аргументе. Это быть может порядок по возрастанию либо по убыванию. Крайний установлен по дефлоту, если поле «Порядок» бросить пустым либо поставить туда цифру 0. Синтаксис этого выражения смотрится последующим образом:
Выше были описаны лишь самые пользующиеся популярностью и нужные статистические функции в Экселе. По сути их в разы больше. Тем не наименее, главный принцип действий у их схожий: обработка массива данных и возврат в обозначенную ячейку результата вычислительных действий.
Мы рады, что смогли посодействовать Для вас в решении задачи.
Кроме данной нам статьи, на веб-сайте еще 12327 инструкций.
Добавьте веб-сайт Lumpics.ru в закладки (CTRL+D) и мы буквально еще пригодимся для вас.
Отблагодарите создателя, поделитесь статьей в соц сетях.
Опишите, что у вас не вышло. Наши спецы постараются ответить очень стремительно.
Статистические функции в Excel
В этом разделе даётся обзор неких более нужных статистических функций Excel.
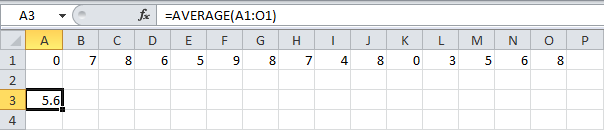
СРЗНАЧ
Функция СРЗНАЧ (AVERAGE) употребляется для вычисления среднего арифметического значения. Аргументы могут быть заданы, к примеру, как ссылка на спектр ячеек.
СРЗНАЧЕСЛИ
Чтоб вычислить среднее арифметическое ячеек, удовлетворяющих данному аспекту, используйте функцию СРЗНАЧЕСЛИ (AVERAGEIF). Ах так, к примеру, можно вычислить среднее арифметическое значение для всех ячеек спектра A1:O1, значение которых не равно нулю (<>0).
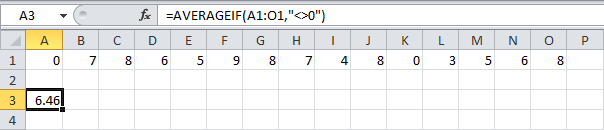
Замечание: Символ <> значит НЕ РАВНО. Функция СРЗНАЧЕСЛИ весьма похожа на функцию СУММЕСЛИ.
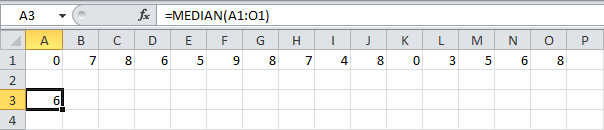
МЕДИАНА
С помощью функции МЕДИАНА (MEDIAN) можно найти медиану (середину) набора чисел.
Функция МОДА (MODE) находит более нередко встречающееся число в наборе чисел.
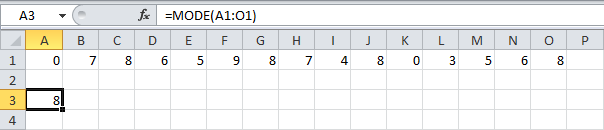
Обычное отклонение
Чтоб вычислить обычное отклонение, используйте функцию СТАНДОТКЛОН (STDEV).
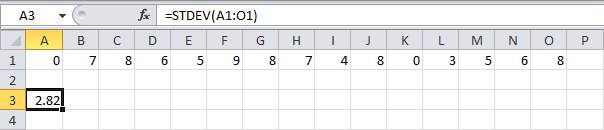
С помощью функции МИН (MIN) можно отыскать малое значение из набора чисел.
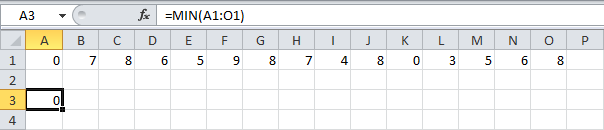
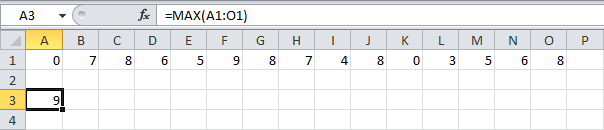
С помощью функции МАКС (MAX) можно отыскать наибольшее значение из набора чисел.
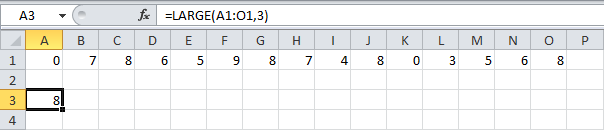
НАИБОЛЬШИЙ
Ах так с помощью функции НАИБОЛЬШИЙ (LARGE) можно отыскать третье наибольшее значение из набора чисел.
НАИМЕНЬШИЙ
Ах так можно отыскать 2-ое меньшее значение с помощью функции НАИМЕНЬШИЙ (SMALL).