Поиск последнего значения крайней строчки в столбце Excel
При составлении формул в Excel нередко возникает необходимость отыскать последнюю строчку либо получить крайнее значение в столбце таблицы с данными. Тут следует учесть несколько критерий, поставленных перед поиском: будет ли перечень значений в столбце неразрывным либо содержать пустые ячейки? Какие это значения: текст, числа? От этих причин зависит тип применяемых формул.
Как отыскать последнюю заполненную строчку в столбце таблицы Excel
Ниже на рисунке представлен неотсортированный перечень фактур. Допустим нам нужно отыскать последнюю строчку с фактурой в перечне номеров фактур. Обычным методом поиска крайней позиции в столбце является внедрение функции ИНДЕКС и подсчет всех позиций перечня с целью определения номера крайней строчки.
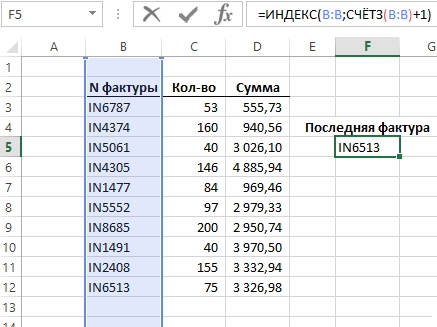
Функция ИНДЕКС применена с одним столбцом просит только указать один аргумент с номером строчки. 3-ий необязательный для наполнения аргумент в данной ситуации не употребляется. Функция СЧЁТЗ употребляется с целью подсчитывания непустых ячеек в столбце B. Ее итоговый итог вычисления следует прирастить на число +1, потому что в первой строке пустая ячейка. Функция ИНДЕКС в данном примере возвращает 12-ую строчку в столбце B.
Функция СЧЁТЗ подсчитывает ячейки содержащие значения: числа, текстовые строчки, даты и все любые остальные значения кроме пустых ячеек. Если ваши данные содержат пустые ячейки, которые разрывают целостность списков, тогда эта формула не будет возвращать правильных результатов вычисления.
Поиск последнего числа в столбце с пустыми ячейками Excel
Функции ИНДЕКС и СЧЁТЗ отлично употребляются для поиска значений в случае, когда спектр начальных данных не содержит пустых ячеек и является неразрывным. Если же начальных спектр ячеек содержит пустые ячейки, а разыскиваемыми значениями являются числа, можно пользоваться функцией ПРОСМОТР с весьма огромным числовым значением в аргументах. Данная техника применяется при помощи составления последующей формулы:
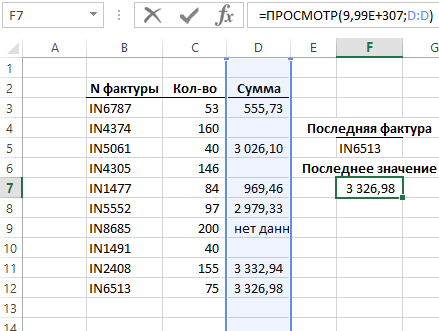
Разыскиваемое значение в данной формуле (единица с 308 знаками) – это самое огромное число доступное в программке Excel. Потому что функция ПРОСМОТР не имела шансов отыскать большего значения чем разыскиваемое, она закончила свое вычисление на крайнем отысканном числовом значении, которую и возвратила в итог.
Что означает число с буковкой E в Excel?
Число такое как, к примеру, 9,99E+307 записано в экспоненциальном формате. Число перед буковкой E имеет одну цифру 0-9 и лишь две числа опосля запятой. Число опосля буковкы E означает количество разрядов, на которые следует сдвинуть запятую (307 в данном примере), чтоб получить числовое значение, записанное обычным методом. Плюс означает, что запятую следует смещать в право, а минус – на лево. К примеру, запись 4,32E-02 значит число, записанное в десятичной дроби 0,0432.
Функция ПРОСМОТР имеет преимущество перед иными функциями в том, что она возвращает крайнее число даже тогда, когда ячейки в просматриваемом спектре могут быть не только лишь пустыми, да и содержать текстовые строчки, коды ошибок либо даты.
Поиск последнего значения в столбце либо строке — Excel

Вы сможете употреблять функцию ПРОСМОТР, чтоб отыскать последнюю непустую ячейку в столбце.
| 1 | = ПРОСМОТР (2,1 / (B: B ""); B: B) |
Давайте пройдемся по данной формуле.
Часть формулы B: B ”” возвращает массив, содержащий значения True и False:
| 1 | = ПРОСМОТР (2,1 / ( <ЛОЖЬ; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА; ИСТИНА; ЛОЖЬ;…); B: B) |
Эти логические значения преобразуются в 0 либо 1 и употребляются для деления 1.
| 1 | = ПРОСМОТР (2; <# DIV / 0!; 1; 1; 1; 1; 1; # DIV / 0!;; B: B) |
Это lookup_vector для функции LOOKUP. В нашем случае lookup_value равно 2, но наибольшее значение в lookup_vector равно 1, потому функция LOOKUP будет соответствовать крайней 1 в массиве и возвратит соответственное значение в result_vector.
Если вы убеждены, что в столбце есть лишь числовые значения, данные начинаются с строчки 1, а спектр данных непрерывен, вы сможете употреблять несколько наиболее ординарную формулу с функциями ИНДЕКС и СЧЁТ.
| 1 | = ИНДЕКС (B: B; СЧЁТ (B: B)) |
Функция COUNT возвращает количество ячеек, заполненных данными в непрерывном спектре (4), а функция INDEX, таковым образом, дает значение ячейки в данной соответственной строке (4-я).
Чтоб избежать вероятных ошибок, когда ваш спектр данных содержит смесь числовых и нечисловых значений либо даже несколько пустых ячеек, вы сможете употреблять функцию LOOKUP совместно с функциями ISBLANK и NOT.
| 1 | = ПРОСМОТР (2,1 / (НЕ (ПУСТОЙ (B: B))); B: B) |

Функция ISBLANK возвращает массив, содержащий значения True и False, надлежащие единицам и нулям. Функция NOT изменяет True (т.е. 1) на False и False (т.е. 0) на True. Если мы инвертируем этот результирующий массив (при делении 1 на этот массив), мы получим результирующий массив, содержащий опять # DIV / 0! ошибок и единиц, которые можно употреблять как поисковый массив (lookup_vector) в нашей функции LOOKUP. Многофункциональные способности функции LOOKUP будут таковыми же, как и в нашем первом примере: она возвращает значение вектора результатов в позиции крайней единицы в поисковом массиве.
Когда для вас необходимо возвратить номер строчки с крайней записью, вы сможете поменять формулу, применяемую в нашем первом примере, совместно с функцией ROW в вашем result_vector.
| 1 | = ПРОСМОТР (2,1 / (B: B ""); СТРОКА (B: B)) |
Крайнее значение в строке
Чтоб получить значение крайней непустой ячейки в строке, заполненной числовыми данными, вы сможете употреблять аналогичный подход, но с иными функциями: функцию OFFSET совместно с функциями MATCH и MAX.
| 1 | = СМЕЩЕНИЕ (ссылка, строчки, столбцы) |
| 1 | = СМЕЩЕНИЕ (B2,0; ПОИСКПОЗ (МАКС (B2: XFD2) + 1; B2: XFD2,1) -1) |
Поглядим, как работает эта формула.
Функция ПОИСКПОЗ
Мы используем функцию MATCH, чтоб «подсчитать», сколько значений ячеек меньше 1 + максимум всех значений в строке 2, начиная с B2.
| 1 | = ПОИСКПОЗ (искомое_значение, искомое_массив, [тип_соответствия]) |
| 1 | = ПОИСКПОЗ (МАКС (B2: XFD2) + 1; B2: XFD2,1) |
Lookup_value функции MATCH является наибольшим из всех значений в строке2 + 1. Так как это значение, разумеется, не существует в строке2, а match_type установлено в 1 (меньше либо равно lookup_value), функция MATCH возвратит Позиция крайней «испытанной» ячейки в массиве, другими словами количество ячеек, заполненных данными в спектре B2: XFD2 (XFD — самый крайний столбец в новейших версиях Excel).
СМЕЩЕНИЕ Функция
Потом мы используем функцию OFFSET, чтоб получить значение данной ячейки, положение которой было возвращено функцией MATCH.
Excel крайнее значение в строке
За определенный период времени ведется регистр количества проданного продукта в магазине. Нужно часто выслеживать крайний выданный из магазина продукт. Для этого необходимо показать последнюю запись в столбце наименования продуктов. Чтоб просто поглядеть на крайнее значение столбца, довольно переместить курсор на всякую его ячейку и надавить комбинацию жарких кнопок CTRL + стрелка в низ (↓). Но почаще всего юзеру приходится с крайним значением столбца делать разные вычислительные операции в Excel. Потому лучше его получить в качестве значения для отдельной ячейки.
Поиск последнего значения в столбце Excel
Схематический регистр продуктов, выданных с магазина:
Чтоб иметь возможность повсевременно следить, какой продукт зарегистрирован крайним, в отдельную ячейку E1 введем формулу:
Итог выполнения формулы для получения последнего значения:
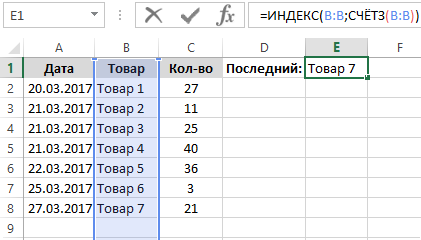
Разбор принципа деяния формулы для поиска последнего значения в столбце:
Главную роль берет на себя функция =ИНДЕКС(), которая обязана возвращать содержимое ячейки таблицы где пересекаются определенная строчка и столбец. В качестве первого аргумента функции ИНДЕКС выступает неизменяемая константа, а конкретно ссылка на целый столбец (B:B). Во 2-м аргументе находится номер строчки с крайним заполненным значением столбца B. Чтоб выяснить этот номер строчки употребляется функция СЧЁТЗ, которая возвращает количество непустых ячеек в спектре. Соответственно это число равно номеру крайней непустой строчки в столбце B и употребляется как 2-ой аргумент для функции ИНДЕКС, которая сходу возвращает крайнее значение столбца B в отдельной ячейке E1.
Внимание! Все записи в столбце B должны быть неразрывны (без пустых ячеек до последнего значения).
Необходимо отметить что данная формула является динамической. При добавлении новейших записей в столбец B итог в ячейке E1 будет автоматом обновляться.
Описание функции
Функция =ПОСЛЕДНЕЕВСТРОКЕ(ЯЧЕЙКА) имеет один аргумент.
- ЯЧЕЙКА – ссылка на всякую ячейку из строчки, в которой нужно отыскать крайнее непустое значение.
Пример
Определение значения крайней непустой ячейки в строке.
Найдем номер строчки крайней заполненной ячейки в столбце и перечне. По номеру строчки найдем и само значение.
Разглядим спектр значений, в который часто заносятся новейшие данные.
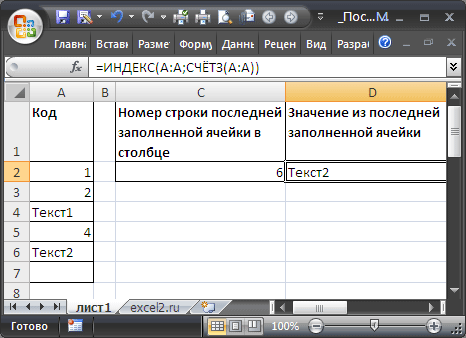
Спектр без пропусков и начиная с первой строчки
В случае, если в столбце значения вводятся, начиная с первой строчки и без пропусков, то найти номер строчки крайней заполненной ячейки можно формулой:
=СЧЁТЗ(A:A))
Формула работает для числовых и текстовых диапазонов (см. Файл примера )
Значение из крайней заполненной ячейки в столбце выведем при помощи функции ИНДЕКС() :
=ИНДЕКС(A:A;СЧЁТЗ(A:A))
Ссылки на целые столбцы и строчки довольно ресурсоемки и могут замедлить пересчет листа. Если есть уверенность, что при вводе значений юзер не выйдет за границы определенного спектра, то лучше указать ссылку на спектр, а не на столбец. В этом случае формула будет смотреться так:
=ИНДЕКС(A1:A20;СЧЁТЗ(A1:A20))
Спектр без пропусков в любом месте листа
Если перечень, в который вводятся значения размещен в спектре E8:E30 (т.е. не начинается с первой строчки), то формулу для определения номера строчки крайней заполненной ячейки можно записать последующим образом:
=СЧЁТЗ(E9:E30)+СТРОКА(E8)
Формула СТРОКА(E8) возвращает номер строчки заголовка перечня. Значение из крайней заполненной ячейки перечня выведем при помощи функции ИНДЕКС() :
=ИНДЕКС(E9:E30;СЧЁТЗ(E9:E30))
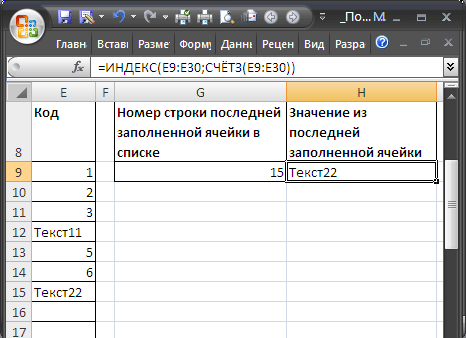
Спектр с пропусками (числа)
В случае наличия пропусков (пустых строк) в столбце, функция СЧЕТЗ() будет возвращать неверный (уменьшенный) номер строчки: оно и понятно, ведь эта функция подсчитывает лишь значения и не учитывает пустые ячейки.
Если спектр заполняется числовыми значениями, то для определения номера строчки крайней заполненной ячейки можно употреблять формулу =ПОИСКПОЗ(1E+306;A:A;1) . Пустые ячейки и текстовые значения игнорируются.
Потому что в качестве просматриваемого массива указан целый столбец (A:A), то функция ПОИСКПОЗ() возвратит номер крайней заполненной строчки. Функция ПОИСКПОЗ() (с третьим параметром =1) находит позицию большего значения, которое меньше либо равно значению первого аргумента (1E+306). Правда, для этого требуется, чтоб массив был отсортирован по возрастанию. Если он не отсортирован, то эта функция возвращает позицию крайней заполненной строчки столбца, т.е. то, что нам необходимо.
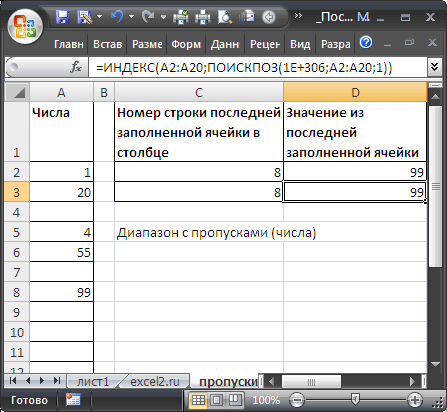
Чтоб возвратить значение в крайней заполненной ячейке перечня, размещенного в спектре A2:A20, можно употреблять формулу:
=ИНДЕКС(A2:A20;ПОИСКПОЗ(1E+306;A2:A20;1))
Спектр с пропусками (текст)
В случае необходимости определения номера строчки последнего текстового значения (также при наличии пропусков), формулу необходимо переработать:
=ПОИСКПОЗ("*";$A:$A;-1)
Пустые ячейки, числа и текстовое значение Пустой текст ("") игнорируются.
Спектр с пропусками (текст и числа)
Если столбец содержит и текстовые и числовые значения, то для определения номера строчки крайней заполненной ячейки можно предложить всепригодное решение:
=МАКС(ЕСЛИОШИБКА(ПОИСКПОЗ("*";$A:$A;-1);0);
ЕСЛИОШИБКА(ПОИСКПОЗ(1E+306;$A:$A;1);0))
Функция ЕСЛИОШИБКА() нужна для угнетения ошибки возникающей, если столбец A содержит лишь текстовые либо лишь числовые значения.
Остальным всепригодным решением является формула массива:
=МАКС(СТРОКА(A1:A20)*(A1:A20<>""))
Опосля ввода формулы массива необходимо надавить CTRL + SHIFT + ENTER. Предполагается, что значения вводятся в спектр A1:A20. Лучше задать фиксированный спектр для поиска, т.к. внедрение в формулах массива ссылок на целые строчки либо столбцы является довольно ресурсоемкой задачей.
Значение из крайней заполненной ячейки, в этом случае, выведем при помощи функции ДВССЫЛ() :
=ДВССЫЛ("A"&МАКС(СТРОКА(A1:A20)*(A1:A20<>"")))
Как обычно, опосля ввода формулы массива необходимо надавить CTRL + SHIFT + ENTER заместо ENTER.
СОВЕТ:
Как видно, наличие пропусков в спектре значительно усложняет подсчет. Потому имеет смысл при заполнении и проектировании таблиц придерживаться правил приведенных в статье Советы по построению таблиц.
Как получить крайнее значение в столбце в Гугл Таблицах (формула поиска)
Если вы работаете с повсевременно расширяющимися данными (когда вы продолжаете добавлять новейшие значения в столбец либо в строчку), то время от времени для вас может потребоваться выяснить, какое значение в столбце в Гугл Таблицах будет крайним .
Хотя вы постоянно сможете прокрутить столбец вниз и проверить вручную, это не безупречное решение. К счастью, это может быть благодаря маленькому волшебству формул в таблицах Гугл.
В этом уроке я покажу для вас, как употреблять формулу для получения последнего значения в столбце в Гугл Таблицах (и то, и другое, когда у вас есть числа либо текст, либо и то, и другое в столбце).
Получить крайний номер в столбце (когда у вас есть числа)
Представим, у вас есть набор данных, показанный ниже, и вы желаете стремительно выяснить крайнее значение в этих данных.
 Приведенная ниже формула сделает это:
Приведенная ниже формула сделает это:
 Приведенная выше формула даст для вас верный итог, даже если у вас есть пустые ячейки в наборе данных. Она также дает для вас лишь крайнее числовое значение. Если у вас есть ячейка с текстовой строчкой опосля последнего числового значения, эта формула все равно даст для вас числовое значение.
Приведенная выше формула даст для вас верный итог, даже если у вас есть пустые ячейки в наборе данных. Она также дает для вас лишь крайнее числовое значение. Если у вас есть ячейка с текстовой строчкой опосля последнего числового значения, эта формула все равно даст для вас числовое значение.
Как работает эта формула?
Сейчас давайте разберемся в гениальности данной формулы.
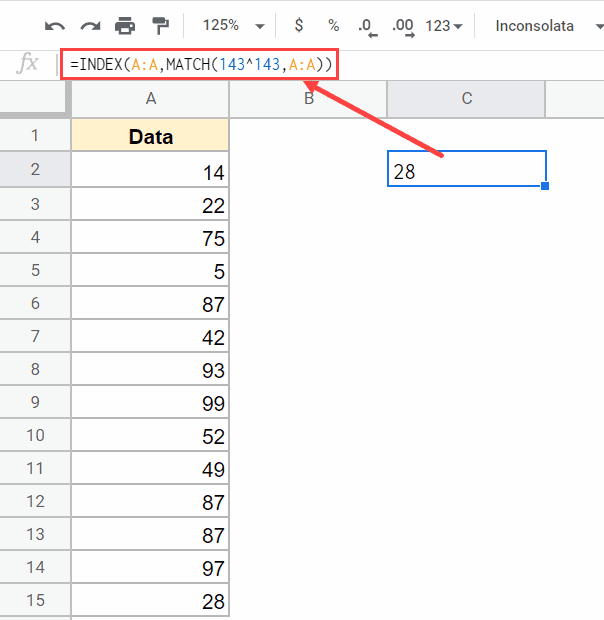
Я употреблял функцию ПОИСКПОЗ (MATCH), чтоб выяснить позицию ячейки с крайним номером в столбце.
Итак, если у меня есть столбец с 10 числами (без пустых ячеек), функция сравнения даст мне 10, что является позицией крайней ячейки с номером в наборе данных.
При помощи функции ПОИСКПОЗ вы сможете выполнить поиск четкого либо ориентировочного совпадения. Когда вы выполняете поиск четкого совпадения, функция ПОИСКПОЗ выдаст для вас позицию ячейки лишь в том случае, если она находит четкое совпадение.
В этом примере я использую ориентировочное совпадение, так как я не понимаю последнего числа (и также есть возможность, что могут быть повторения)
Вот часть формулы MATCH:
1-ый аргумент — это значение поиска (143 ^ 143 в приведенной выше формуле). Это значение, которое будет находить совпадение в обозначенном наборе данных.
И 2-ой аргумент — это спектр, в котором функция ПОИСКПОЗ будет находить 1-ый аргумент. и так как мы желаем выяснить крайнее значение в столбце, я указал весь столбец в качестве спектра поиска.
Так как я не указал 3-ий аргумент, он автоматом воспринимает его как 1 (что показывает на ориентировочный поиск)
Мысль данной формулы состоит в том, чтоб иметь вправду огромное значение поиска (143 ^ 143 — что-то, что навряд ли будет в наборе данных), чтоб функция ПОИСКПОЗ продолжала работать до конца, и когда она не сумеет отыскать это value, заместо этого он возвратит позицию крайней заполненной ячейки.
В нашем примере набора данных часть соответствия формулы возвращает 74, что является позицией последнего числа в наборе данных.
Сейчас мы можем просто употреблять это число в индексной функции, чтоб получить фактическое значение (в данном примере 54).
Получить крайнее текстовое значение в столбце
Представим, у вас есть набор данных, показанный ниже, и вы желаете стремительно выяснить имя последнего человека в перечне.
 Ниже приведена формула, которая сделает это за вас.
Ниже приведена формула, которая сделает это за вас.
Как работает эта формула?
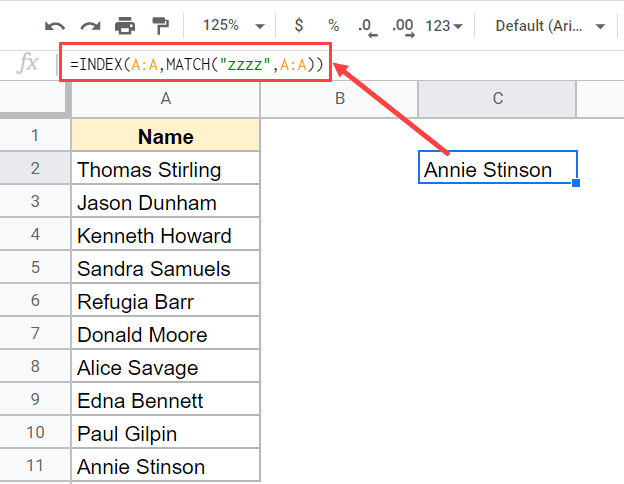
В приведенной выше формуле употребляется ориентировочная формула ПОИСКПОЗ, которая проходит по всему списку и возвращает имя, более близкое к разыскиваемому значению.
В нашем примере я употреблял «zzzz» в качестве значения поиска. Так как Z — это крайний алфавит, а ‘zzzz’ навряд ли будет частью текста, в котором мы отыскиваем, функция ПОИСКПОЗ будет работать до конца, и когда она не сумеет отыскать ничего близкого к этому значению, она перейдет к чтоб возвратить позицию последнего значения в столбце.
Это значение позиции потом употребляется индексной функцией для возврата имени в ячейке.
Получить крайнее значение в столбце (в котором есть как числа, так и текст)
Если у вас есть набор данных, содержащий сочетание чисел и текстовых значений, и вы желаете выяснить, какое крайнее значение в столбце (будь то число либо текстовая строчка), вы также сможете просто это создать.
Уловка тут заключается в том, чтоб соединить обе эти формулы (описанные выше) и проверить позицию крайней ячейки с номером и текстовой строчкой и возвратить значение, где значение позиции больше.
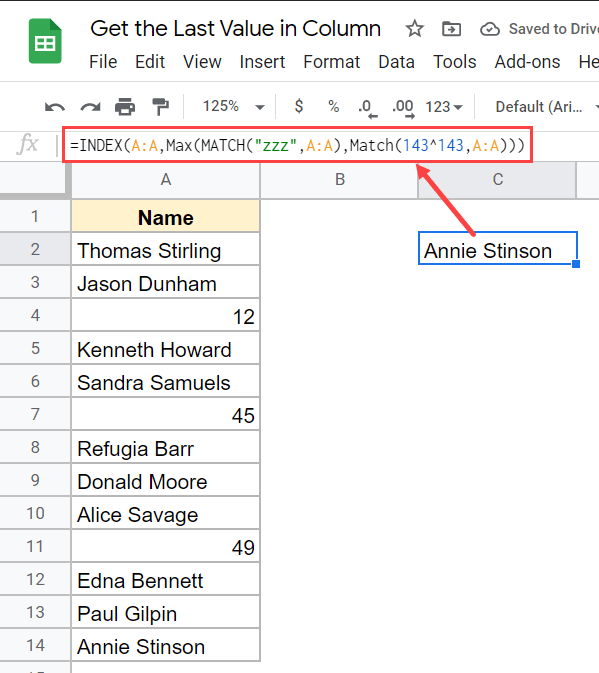
Представим, у вас есть набор данных, показанный ниже, и вы желаете отыскать последнюю заполненную ячейку в столбце.
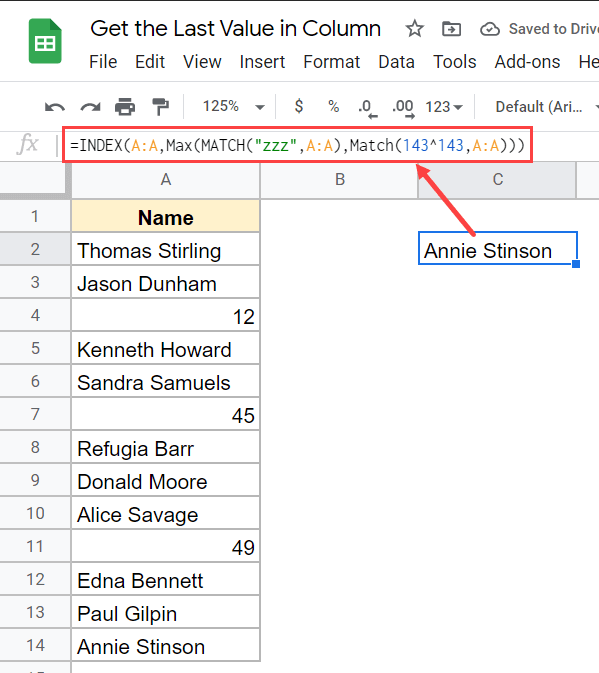 Ниже приведена формула, которая сделает это
Ниже приведена формула, которая сделает это
Как работает эта формула?
Так как мы имеем дело с набором данных, который содержит как числа, так и текстовые значения, нам необходимо употреблять две формулы MATCH — одну для чисел и одну для текстовых строк.
Обе эти формулы сравнения дадут нам число, которое укажет позицию крайней заполненной ячейки с номером и крайней заполненной ячейки с текстовой строчкой.
А потом мы просто используем функцию Max, чтоб найти позицию, которая больше, и употреблять ее в функции индекса для возврата значения.
Итак, это несколько обычных формул поиска, которые вы сможете употреблять для получения последнего значения в столбце в Гугл Таблицах. Формула, которую вы используете, будет зависеть от того, есть ли у вас набор числовых данных, буквенно-цифровой набор данных либо их сочетание.