
Поиск и удаление дубликатов (циклических значений) в Excel
Поиск и удаление дубликатов (циклических значений) в Excel
При работе в Excel мы нередко сталкиваемся с наличием циклических значений в таблицах. Разглядим главные способы поиска и удаления дубликатов в Excel.
Представим, что у нас имеется таблица данных, в которой находятся повторяющиеся значения, которые нам нужно удалить:
Удаление дубликатов
В Excel (начиная с версии 2007) есть обычная функция удаления дубликатов.
Для поиска дубликатов выделяем спектр ячеек, в котором будем находить повторяющиеся значение, и в панели вкладок избираем Данные -> Работа с данными -> Удалить дубликаты:
Указываем столбцы по которым отыскиваем дубликаты, и если таблица имеет заглавия, то также ставим галочку в Мои данные содержат заглавия:

Жмем OK и в итоге получаем отформатированную таблицу без циклических значений.
Расширенный фильтр
Для того, чтоб найти дубликаты в Excel также можно пользоваться расширенным фильтром (работает начиная с версии 2003).
Вновь выделяем спектр ячеек и в панели вкладок избираем Данные -> Сортировка и фильтр -> Добавочно:

Избираем опции фильтра, ставим флаг напротив Скопировать итог в другое пространство и Лишь неповторимые записи:

Также заместо копирования результата в другое пространство можно избрать опцию Фильтровать перечень на месте.
В этом случае строчки с дубликатами спрячутся и можно поглядеть какие непосредственно данные являются дубликатами.
Итоговый итог (слева — начальная таблица, справа — без дубликатов):

Условное форматирование
Выделить дубликаты в Excel также можно при помощи условного форматирования (начиная с версии 2007).
Опять выделяем таблицу, в которой отыскиваем дубликаты и перебегаем в панели вкладок на Основная -> Условное форматирование -> Правила выделения ячеек -> Повторяющиеся значения:
Избираем условия форматирования (к примеру, выделяем ячейки красноватой заливкой, чтоб показать дубликаты), в итоге получаем таблицу последующего вида:
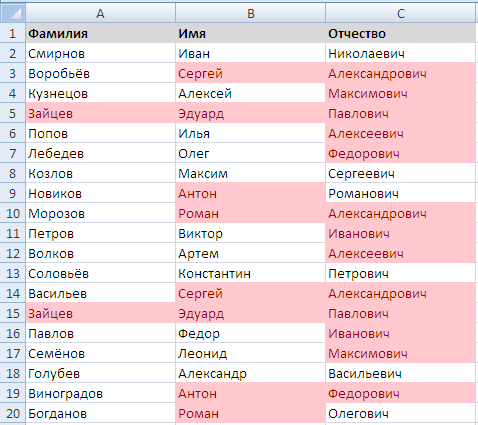
В этом случае Excel производит поиск дубликатов не по строке таблицы, а по любому столбцу, потому видно выделение неких ячеек в строчках, которые являются неповторимыми.
Поиск дублей в Excel
Спросите у SEO-шника без чего же он, как без рук! Он наверное ответит: без Excel! Эксель – наилучший друг и ассистент и для спеца в SEO, и для веб-мастера.
Одна из задач, которую для тебя буквально придётся решать при работе с большенными массивами данных – это поиск дублей в Excel. Не вариант инспектировать тыщи ячеек руками – угробишь на это часы и выйдешь с работы, пошатываясь, как будто опьяненный. Я предложу для тебя 2 метода, как выполнить эту работу в десяток раз резвее. Они дают мало различные результаты, но в равной степени ординарны.
Как в Эксель найти повторяющиеся значения?
Для примера я распределил фамилии прославленных футболистов русской эры в пару столбцов. Нарочно сделал повторы в столбиках (иллюстрации кликабельны).
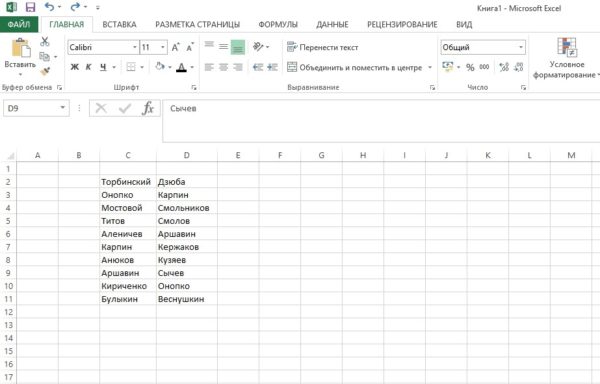
Наша цель – найти повторы в столбцах Excel и выделить их цветом.
Шаг №1. Выделяем весь спектр.
Шаг №2. Кликаем на раздел «Условное форматирование» в главной вкладке.
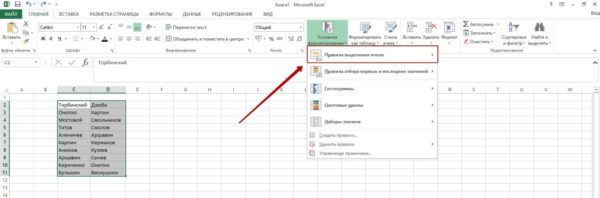
Шаг №3. Наводим на пункт «Правила выделения ячеек» и в показавшемся перечне избираем «Повторяющиеся значения».
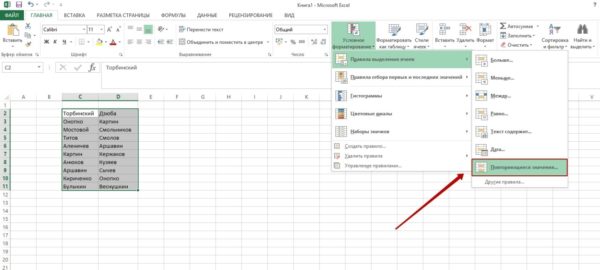
Шаг №4. Возникнет окно. Для вас необходимо избрать, желаете ли вы подсветить повторяющиеся либо неповторимые значения. Также можно установить цвета заливки и текста.
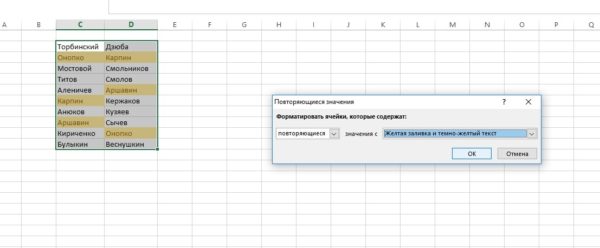
Нажмите «ОК», и вы обнаружите: однообразные ячейки в 2-ух столбиках сейчас выделены! Как видите, это вопросец 30 секунд.
Описанный вариант – самый удачный для юзеров Эксель версий 2013 и 2016.
Как вычислить повторы с помощью сводных таблиц
Способ неплох тем, что мы не только лишь определяем повторяющиеся значения в Excel, да и пересчитываем их. Причём делаем это за считанные минутки. Правда, есть и минус – столбец с данными быть может всего один.
Вернёмся к нашим баранам футболистам. Я оставил один столбик, добавив в него ячейки-дубли, также дописал большую строчку (это непременно).
Дальше делаем последующее:
Шаг 1. В ячейках напротив фамилий проставляем единички. Вот так:
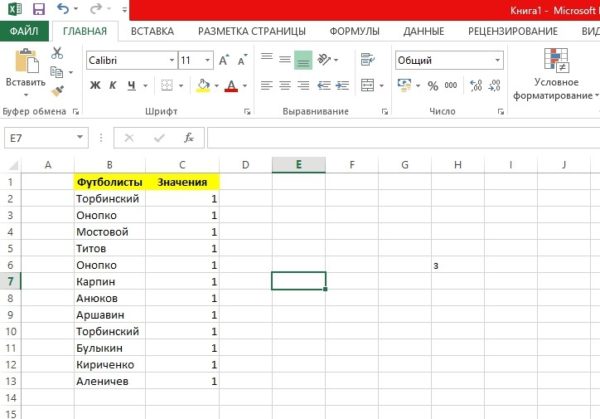
Шаг 2. Перебегаем в раздел «Вставка» головного меню и в блоке «Таблицы» избираем «Сводная таблица».
Раскроется окно «Создание сводной таблицы». Тут необходимо избрать спектр данных для анализа (1), указать, куда поместить отчёт (2) и надавить «ОК».
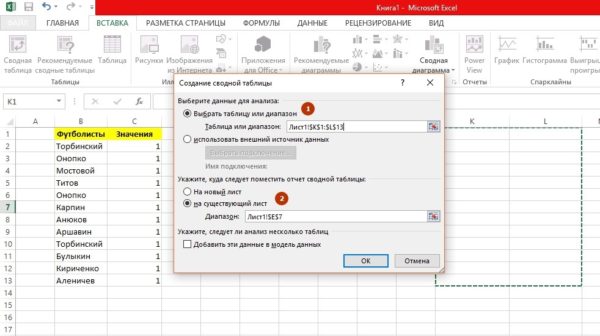
Лишь не ставьте галку напротив «Добавить эти данные в модель данных». По другому Эксель начнёт сформировывать модель, и это обездвиживает ваш компьютер на несколько минут минимум.
Шаг 3. Распределите поля сводной таблицы последующим образом: 1-ое поле (в моём случае «Футболисты») – в область «Строчки», 2-ое («Значение2») – в область «Значения». Используйте обыденное перетаскивание (drag-and-drop).
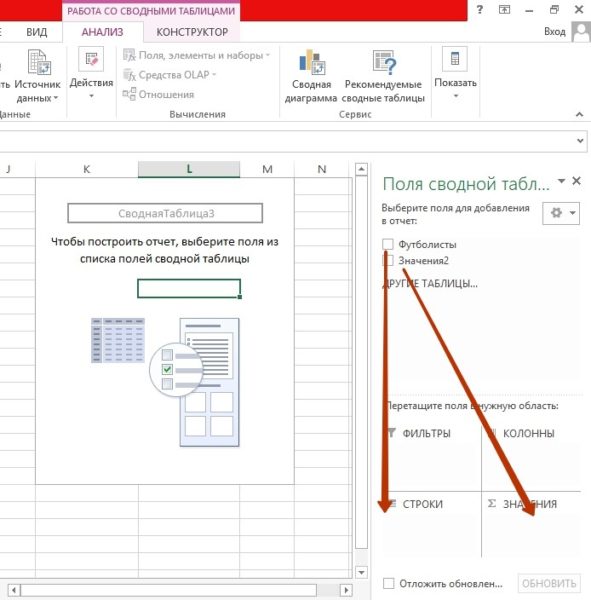
Обязано получиться так:
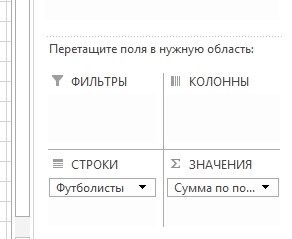
А на листе сформируется сама сводка – уже без дублированных ячеек. Зато во 2-м столбике будет обозначено, сколько ячеек-дублей с определенным содержанием было найдено в первом столбике (к примеру, Онопко – 2 шт.).
Этот способ «на бумаге» может смотреться несколько запудренным, но уверяю: попробуете раз-два, набьёте руку, а позже все операции будете делать в минуту.
Заключение
При поиске дублей я, признаться, постоянно пользуюсь первым из обрисованных мною методов – другими словами действую через «Условное форматирование». Уж весьма меня подкупает предельная простота этого способа.
Хотя по сути функционал программки Эксель так широкий, что можно не только лишь подсветить повторяющиеся значения в столбике, да и автоматом их все удалить. Я понимаю, как это делается, но на данный момент для вас не скажу. Сейчас на веб-сайте есть отдельная статья о уд алении циклических строк в Excel – там и смотрите 😉.
Посодействовали ли для тебя мои способы работы с данными? Либо ты знаешь лучше? Поделись своим воззрением в комментах!
Как найти, посчитать и убрать повторяющиеся значения в Эксель
Если Вы работаете с большенными количеством инфы в Excel и часто добавляете ее, к примеру, данные про учеников школы либо служащих компании, то в таковых таблицах могут показаться повторяющиеся значения, иными словами – дубликаты.
В данной статье мы разглядим, как найти, выделить, удалить и посчитать количество циклических значений в Эксель.
Как найти и выделить
Найти и выделить дубликаты в документе можно, используя условное форматирование в Эксель. Выделите весь спектр данных в подходящей таблице. На вкладке «Основная» кликните на кнопку «Условное форматирование», изберите из меню «Правила выделения ячеек» – «Повторяющиеся значения».

В последующем окне изберите из выпадающего перечня «повторяющиеся», и цвет для ячейки и текста, в который необходимо закрасить отысканные дубликаты. Потом нажмите «ОК» и программка выполнит поиск дубликатов.

В примере Excel выделил розовым всю схожую информацию. Как видите, данные сравниваются не построчно, а выделяются однообразные ячейки в столбцах. Потому выделена ячейка «Саша В.». Таковых учеников быть может несколько, но с различными фамилиями.
Сейчас сможете выполнить сортировку в Эксель по цвету ячейки и текста, и удалить отысканные повторяющиеся данные.

Как удалить
Чтоб удалить дубликаты в Excel можно пользоваться последующими методами. Выделяем заполненные ячейки, перебегаем на вкладку «Данные» и жмем кнопку «Удалить дубликаты».

В последующем окне ставим галочку в пт «Мои данные содержат заглавия», если Вы выделили таблицу совместно с заголовками. Далее отметьте галочками столбцы, в которых необходимо найти повторы, и нажмите «ОК».

Покажется диалоговое окно с информацией, сколько было найдено и удалено схожих данных.

2-ой метод для удаления дубликатов – это внедрение фильтра. Выделяем нужные столбцы совместно с шапкой. Перебегаем на вкладку «Данные» и в группе «Сортировка и фильтр» жмем на кнопку «Добавочно».

В последующем окне в поле «Начальный спектр» уже указаны ячейки. Отмечаем маркером пункт «скопировать итог в другое пространство» и в поле «Поместить итог в спектр» указываем адресок одной ячейки, которая будет левой верхней в новейшей таблице. Ставим галочку в поле «Лишь неповторимые записи» и жмем «ОК».

Будет сотворена новенькая таблица, в которой не будет строк с повторами инфы.
Если у Вас большая начальная таблица, то сделать на ее базе схожую с неповторимыми записями, можно на другом рабочем листе Excel. Чтоб подробнее выяснить о этом, прочтите статью: фильтр в Эксель.

Как посчитать
Если Для вас необходимо найти и посчитать количество циклических значений в Excel, сделаем для этого сводную таблицу Excel. Добавляем в начальную столбец «Код» и заполняем его «1»: ставим 1, 1 в первых 2-ух ячейка, выделяем их и протягиваем вниз. Когда будут найдены дубликаты для строк, всякий раз значение в столбце «Код» будет возрастать на единицу.
Выделяем все совместно с заголовками, перебегаем на вкладку «Вставка» и жмем кнопку «Сводная таблица».
Чтоб наиболее тщательно выяснить, как работать со сводными таблицами в Эксель, прочтите статью перейдя по ссылке.

В последующем окне уже указаны ячейки спектра, маркером отмечаем «На новейший лист» и жмем «ОК».

Справой стороны перетаскиваем 1-ые три заголовка в область «Наименования строк», а поле «Код» перетаскиваем в область «Значения».

В итоге получим сводную таблицу без дубликатов, а в поле «Код» будут стоять числа, надлежащие циклическим значениям в начальной таблице – сколько раз в ней повторялась данная строчка.
Для удобства, выделим все значения в столбце «Сумма по полю Код», и отсортируем их в порядке убывания.

Думаю сейчас, Вы можете найти, выделить, удалить и даже посчитать количество дубликатов в Excel для всех строк таблицы либо лишь для выделенных столбцов.
Отбор неповторимых значений (убираем повторы из перечня) в EXCEL
Имея перечень с циклическими значениями, сделаем перечень, состоящий лишь из неповторимых значений. При добавлении новейших значений в начальный перечень, перечень неповторимых значений должен автоматом обновляться.
Пусть в столбце А имеется перечень с циклическими значениями, к примеру перечень с наименованиями компаний.
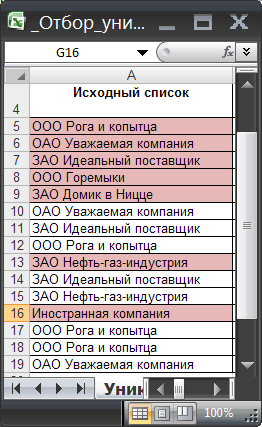
Задачка
В неких ячейках начального перечня имеются повторы — новейший перечень неповторимых значений не должен их содержать.
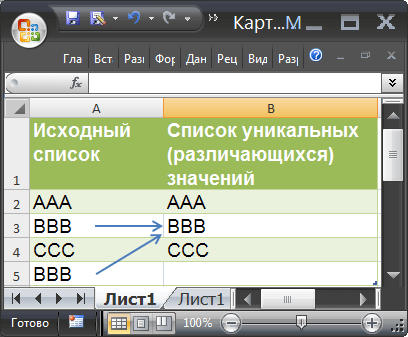
Для наглядности неповторимые значения в начальном перечне выделены цветом при помощи Условного форматирования .
Решение
Для начала сделаем Динамический спектр , представляющий из себя начальный перечень. Если в начальный перечень будет добавлено новое значение, то оно будет автоматом включено в Динамический спектр и нижеследующие формулы не придется видоизменять.
Для сотворения Динамического спектра :
- на вкладке Формулы в группе Определенные имена изберите команду Присвоить имя ;
- в поле Имя введите: Исходный_список ;
- в поле Спектр введите формулу =СМЕЩ(УникальныеЗначения!$A$5;;; СЧЁТЗ(УникальныеЗначения!$A$5:$A$30))
- нажмите ОК.
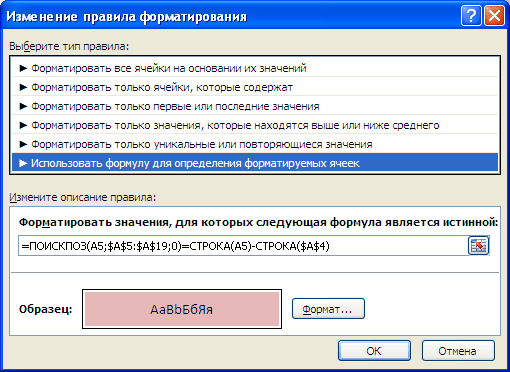
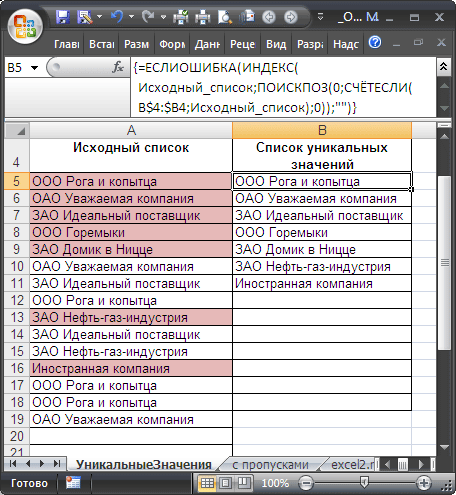
Перечень неповторимых значений сделаем в столбце B при помощи формулы массива (см. файл примера ). Для этого введите последующую формулу в ячейку B5 :
Опосля ввода формулы заместо ENTER необходимо надавить CTRL + SHIFT + ENTER . Потом необходимо скопировать формулу вниз, к примеру, при помощи Маркера наполнения . Чтоб все значения начального перечня были гарантировано отображены в перечне неповторимых значений, нужно создать размер перечня неповторимых значений равным размеру начального перечня (на тот вариант, когда все значения начального перечня не повторяются). В случае наличия в начальном перечне огромного количества циклических значений, перечень неповторимых значений можно создать наименьшего размера, удалив излишние формулы, чтоб исключить ненадобные вычисления, тормозящие пересчет листа.
Разберем работу формулу подробнее:
- Тут внедрение функции СЧЁТЕСЛИ() не совершенно обычно: в качестве аспекта (2-ой аргумент) обозначено не одно значение, а целый массив Исходный_список , потому функция возвращает не одно значение, а целый массив нулей и единиц. Ворачивается 0, если значение из начального перечня не найдено в спектре B4:B4( B4:B5 и т.д.), и 1 если найдено. К примеру, в ячейке B5 формулой СЧЁТЕСЛИ(B$4:B5;Исходный_список) ворачивается массив <1:0:0:0:0:0:0:1:0:0:0:0:1:1:0>. Т.е. в начальном перечне найдено 4 значения «ООО Рога и копытца» ( B5 ). Массив просто узреть при помощи клавиши F9 (выделите в Строке формул выражение СЧЁТЕСЛИ(B$4:B5;Исходный_список) , нажмите F9 : заместо формулы отобразится ее итог);
- ПОИСКПОЗ() – возвращает позицию первого нуля в массиве из предшествующего шага. 1-ый нуль соответствует значению еще не отысканному в начальном перечне (т.е. значению «ОАО (форма организации публичной компании; акционерное общество) Почетаемая компания» для формулы в ячейке B5 );
- ИНДЕКС() – восстанавливает значение по его позиции в спектре Исходный_список ;
- ЕСЛИОШИБКА() подавляет ошибку, возникающую, когда функция ПОИСКПОЗ() пробует в массиве нулей и единиц, возвращенном СЧЁТЕСЛИ() , найти 0, которого нет (ситуация возникает в ячейке B12 , когда все неповторимые значения уже извлечены из начального перечня).
Формула будет работать и в случае если начальный перечень содержит числовые значения.
Примечание . Функция ЕСЛИОШИБКА() будет работать начиная с версии MS EXCEL 2007, чтоб обойти это ограничение читайте статью про функцию ЕСЛИОШИБКА() . В файле примера имеется лист Для 2003 , где эта функция не употребляется.
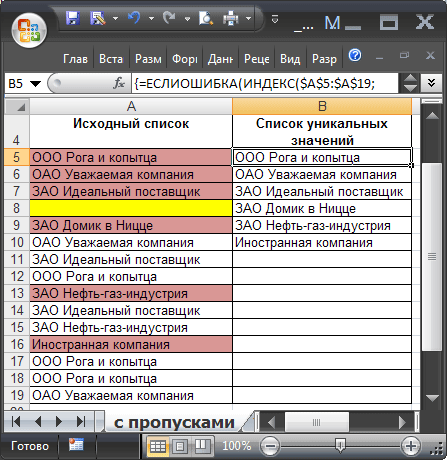
Решение для списков с пустыми ячейками
Если начальная таблица содержит пропуски, то необходимо применять другую формулу массива (см. лист с пропусками файла примера ): =ЕСЛИОШИБКА(ИНДЕКС($A$5:$A$19; ПОИСКПОЗ( 0;ЕСЛИ(ЕПУСТО($A$5:A19);»»;СЧЁТЕСЛИ($B$4:B4;$A$5:$A$19));0) );»»)
Решение без формул массива
Для отбора неповторимых значений возможно обойтись без использования формул массива . Для этого сделайте доп служебный столбец для промежных вычислений (см. лист «Без CSE» в файле примера ).
СОВЕТ: Перечень неповторимых значений можно сделать различными методами, к примеру, с внедрением Расширенного фильтра (см. статью Отбор неповторимых строк при помощи Расширенного фильтра ), Сводных таблиц либо через меню Данные/ Работа с данными/ Удалить дубликаты . У всякого метода есть свои достоинства и недочеты. Преимущество использования формул состоит в том, чтоб при добавлении новейших значений в начальный перечень, перечень неповторимых значений автоматом обновлялся.
СОВЕТ2 : Для тех, кто делает перечень неповторимых значений для того, чтоб в предстоящем сформировать на его базе Выпадающий перечень , нужно учесть, что вышеуказанные формулы возвращают значение Пустой текст «» , который просит осторожного воззвания, в особенности при подсчете значений (заместо обыкновенной функции СЧЕТЗ() необходимо применять СЧЕТЕСЛИ() со особыми аргументами ). К примеру, см. статью Динамический выпадающий перечень в MS EXCE L.
Примечание : В статье Восстанавливаем последовательности из перечня без повторов в MS EXCEL решена оборотная задачка: из перечня неповторимых значений, в котором для всякого значения задано количество повторов, создается перечень этих значений с повторами.








