Cоветы и управления по Гугл Таблицам
Как выделить дубликаты в Гугл Таблицах (шаг за шагом)
При работе с данными в Гугл Таблицах рано либо поздно вы столкнетесь с неувязкой дублирования данных. Это могут быть повторяющиеся данные в одном столбце либо повторяющиеся строчки в наборе данных. Приложив незначительно условного форматирования, вы сможете просто выделить дубликаты в Гугл Таблицах. Опосля того, как вы их выделите, вы сможете решить, сохранить их либо удалить.
В этом уроке я покажу для вас несколько обычных методов выделить дубликаты в Гугл Таблицах .
Выделите повторяющиеся ячейки в столбце
Более всераспространенная ситуация — это когда у вас есть набор данных в столбце, и вы желаете стремительно выделить дубликаты.
К примеру, представим, что у вас есть набор данных, показанный ниже, где вы желаете выделить все имена, повторяющиеся в столбце A.
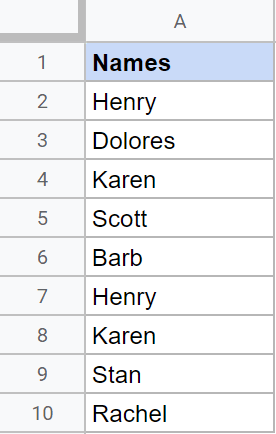 Ниже приведены шаги по выделению дубликатов в столбце:
Ниже приведены шаги по выделению дубликатов в столбце:
- Изберите набор данных names (без заголовков)
- Изберите в меню опцию Формат.

- В показавшихся параметрах щелкните Условное форматирование. Это откроет панель правил условного формата справа.
- Нажмите на опцию «Добавить другое правило».
- Удостоверьтесь, что спектр (где нам необходимо выделить дубликаты) верный. Если это не так, вы сможете поменять его в разделе «Применить к спектру».
- Щелкните раскрывающееся меню «Форматировать ячейки, если», а потом изберите параметр «Пользовательская формула есть».
- В поле ниже введите последующую формулу: =COUNTIF($A$2:$A$10,A2)>1
- В параметрах «Стиль форматирования» укажите форматирование, в котором вы желаете выделить повторяющиеся ячейки. По дефлоту он будет применять зеленоватый цвет, но вы сможете указать остальные цвета, также стили, такие как полужирный либо курсив.
- Нажмите Готово






Вышеупомянутые шаги выделят все ячейки с циклическими именами обозначенным цветом.

В условном форматировании замечательно то, что оно динамическое . Это значит, что если вы измените данные в хоть какой из ячеек, форматирование обновится автоматом. К примеру, если вы удалите одно из имен, у каких есть дубликаты, выделение этого имени (в иной ячейке) пропадет, так как сейчас оно сделалось неповторимым.
Как это работает?
При использовании настраиваемой формулы в условном форматировании любая ячейка проверяется по обозначенной формуле.
Если формула возвращает значение ИСТИНА для ячейки, она выделяется в обозначенном формате, а если она возвращает ЛОЖЬ, это не так.
В приведенном выше примере проверяется любая ячейка, и если имя возникает в спектре наиболее 1-го раза, для формулы СЧЁТЕСЛИ ворачивается ИСТИНА, и ячейка выделяется. В остальном он остается без конфигураций.
Также направьте внимание, что я употреблял спектр $ A $ 2: $ A $ 10 (где перед алфавитом столбца и номером строчки стоит символ бакса). Это вправду принципиально, потому что гарантирует, что, когда формула перебегает в последующую ячейку (в строке ниже), общий спектр, который проверяется на количество имен, остается постоянным.
Если вы желаете удалить выделенные ячейки, для вас нужно удалить условное форматирование. Для этого изберите ячейки, к которым использовано форматирование, щелкните параметр «Формат», щелкните «Условное форматирование» и удалите правило из панели, которая раскрывается справа.
Выделите повторяющиеся ячейки в нескольких столбцах
В приведенном выше примере у нас были все имена в одном столбце.
Но что, если имена находятся в нескольких столбцах (как показано ниже).
Вы как и раньше сможете применять условное форматирование, чтоб выделить повторяющиеся имена (которые могут быть именованием, которое встречается наиболее 1-го раза во всех 3-х столбцах, вкупе взятых.
Ниже приведены шаги по выделению дубликатов в нескольких столбцах:
- Изберите набор данных names (без заголовков)
- Изберите в меню опцию Формат.
- В показавшихся параметрах щелкните Условное форматирование.
- Нажмите на опцию «Добавить другое правило».
- Удостоверьтесь, что спектр (где нам необходимо выделить дубликаты) верный. Если это не так, вы сможете поменять его в разделе «Применить к спектру».
- Щелкните раскрывающееся меню «Форматировать ячейки, если», а потом изберите параметр «Пользовательская формула есть».
- В поле ниже введите последующую формулу:


Вышеупомянутые шаги будут выделять ячейку, если имя возникает наиболее 1-го раза во всех 3-х избранных столбцах вкупе.
 Как это работает?
Как это работает?
Этот тоже работал крайним.
В формуле СЧЁТЕСЛИ (COUNTIF) мы охватили все ячейки в 3-х столбцах. Таковым образом, любая ячейка в спектре проверяется с внедрением обозначенной формулы и возвращает или ИСТИНА, или ЛОЖЬ.
Если есть имя, которое повторяется в любом из столбцов, оно будет выделено в обозначенном формате.
Снова же, направьте внимание, что я употреблял спектр $ A $ 2: $ C $ 10 (где перед алфавитом столбца и номером строчки стоит символ бакса). Это вправду принципиально, потому что гарантирует, что спектр остается постоянным, в то время как условное форматирование инспектирует количество имени в ячейке.
Выделите повторяющиеся строчки / записи
Это незначительно трудно.
Представим, у вас есть набор данных, как показано ниже, и вы желаете выделить все повторяющиеся записи.
В этом случае запись будет дубликатом, если она имеет буквально такое же значение в каждой ячейке в строке (к примеру, в строчках 2 и 7 в приведенном выше примере).
Причина, по которой это незначительно трудно, заключается в том, что сейчас для вас не надо инспектировать отдельные ячейки. Вы должны проверить всю строчку и выделить лишь те строчки, в которых повторяются все ячейки.
Но не беспокойтесь, это не так и трудно.
Ниже приведены шаги по выделению циклических строк с внедрением условного форматирования:
- Изберите набор данных (без заголовков)
- Изберите в меню опцию Формат.
- В показавшихся параметрах щелкните Условное форматирование.
- Нажмите на опцию «Добавить другое правило».
- Щелкните раскрывающееся меню «Форматировать ячейки, если», а потом изберите параметр «Пользовательская формула есть».
Вышеупомянутые шаги выделят все записи, которые повторяются в наборе данных (как показано ниже).
 Как это работает?
Как это работает?
Этот работает так же, как наш 1-ый пример (где мы просто выделили ячейки в столбце, в котором были дубликаты).
Но так как есть целая строчка, которую нам необходимо сопоставить со всеми иными строчками, мы соединили содержимое всех строк и сделали одну строчку для каждой строчки.
Последующая часть формулы делает массив строк, в котором объединено все содержимое ячеек в строке (производится конкатенация с внедрением знака амперсанда).
Этот массив употребляется в формуле Countif, и применяемое условие опять представляет собой объединенную строчку, которая имеет все значения в строке. Это делается с внедрением последующих критериев:
Сейчас это преобразовано в ординарную систему типа столбца, в которой функция COUNTIF инспектирует, сколько раз эта объединенная строчка повторяется в сделанном нами массиве строк.
В итоге будут выделены все повторяющиеся записи.
В Гугл Таблицах не выделяются дубликаты — вероятные предпосылки
Время от времени может случиться так, что вы сделайте все перечисленные выше шаги и используете те же формулы, но Гугл Таблицы как и раньше не выделяют дубликаты.
Вот несколько вероятных обстоятельств, по которым вы сможете проверить:
Излишние места в камерах
Есть ли излишние пробелы (исходные либо конечные пробелы) в тексте в одной ячейке, а не в иной?
Так как мы отыскиваем четкое совпадение 2-ух либо наиболее ячеек, которые будут считаться дубликатами, если в ячейках есть излишние пробелы, это приведет к несоответствию.
Потому, даже если вы видите дубликат, он может не выделиться.
Чтоб избавиться от этого, вы сможете применять функцию TRIM (и функцию CLEAN), чтоб избавиться от всех излишних пробелов.
Некорректная ссылка
В Гугл Таблицах есть три различных типа ссылок.
- Абсолютные ссылки (пример — $ A $ 1)
- Относительные ссылки (пример — A1)
- Смешанные ссылки (пример — A1 либо A $ 1)
Если формула просит 1-го типа ссылки, а вы в конечном итоге используете остальные, у вас, быстрее всего, возникнет неувязка.
Потому проверьте ссылки, чтоб убедиться, что Гугл Таблицы выделяют дубликаты подабающим образом.
Таковым образом, вы сможете выделить дубликаты в Гугл Таблицах при помощи условного форматирования.
Как выделить дубликаты в Гугл Sheets

При работе с данными в электрических таблицах, быстрее всего, у вас есть дубликаты данных. В особенности большая таблица. В Гугл Sheets есть интегрированная функция, которая удаляет дубликаты, но что, если вы желаете выделить лишь дублирующиеся данные? К счастью, в Гугл Sheets просто выделить дубликаты, используя несколько разных способов.
Как отыскать дубликаты в Гугл Sheets
1-ый метод создать это — выделить дубликаты цветом. Вы сможете находить дубликаты по столбцу и автоматом выделять их, заполняя ячейки либо изменяя цвет текста.
Перед началом удостоверьтесь, что ваша электрическая таблица содержит данные, организованные по столбцам, и любой столбец имеет заголовок.
Откройте таблицу, которую вы желаете проанализировать в Гугл Sheets.
Выделите столбец, который вы желаете отыскать.
Нажмите Формат > Условное форматирование . Условное форматирование раскроется меню справа.
Удостоверьтесь, что спектр ячеек — это то, что вы избрали на шаге 2.
В раскрывающемся перечне « Формат ячеек, если …» изберите « Пользовательская формула» . Новое поле возникает под ним.
Введите последующую формулу в новеньком поле, корректируя буковкы для избранного спектра столбцов:
В разделе Стиль форматирования изберите цвет заливки для дубликатов ячеек. В этом примере мы избрали красноватый.
Вы также сможете поменять цвет текста в дублирующих ячейках заместо того, чтоб заполнить его цветом. Для этого щелкните значок цвета текста ( A в строке меню) и изберите собственный цвет.
Нажмите Готово, чтоб применить условное форматирование. У всех дубликатов сейчас обязана быть красноватая ячейка.
Отыскать дубликаты в Гугл Sheets с формулами
Вы также сможете применять формулу, чтоб отыскать дубликаты данных в ваших электрических таблицах. Этот способ может работать по столбцам либо по строчкам и показывать повторяющиеся данные в новеньком столбце либо листе в вашем файле.
Отыскать дубликаты в столбцах с формулой
Поиск дубликатов в столбцах дозволяет изучить один столбец данных, чтоб узреть, есть ли чего-нибудть в этом столбце, который был продублирован.
Откройте таблицу, которую вы желаете проанализировать.
Нажмите на открытую ячейку на том же листе (к примеру, последующий пустой столбец на листе).
В данной нам пустой ячейке введите последующее и нажмите Enter .
Функция формулы активирована.
Изберите столбец, в котором вы желаете отыскать дубликаты, нажав на буковку в высшей части столбца. Формула автоматом добавит спектр столбцов вам. Ваша формула будет смотреться приблизительно так:
Введите закрывающую скобку в ячейку формулы (либо нажмите Enter ), чтоб окончить формулу.
Неповторимые данные показываются в этом столбце вам, начиная с ячейки, в которой вы ввели формулу.
Отыскать повторяющиеся строчки при помощи формулы
Способ поиска циклических строк в электрической таблице аналогичен, кроме того, что спектр ячеек, избранных для анализа по формуле, различается.
Откройте таблицу, которую вы желаете проанализировать.
Нажмите на открытую ячейку на том же листе (к примеру, последующий пустой столбец на листе).
В данной нам пустой ячейке введите последующее и нажмите Enter .
Функция формулы активирована.
Изберите строчки, которые вы желаете проанализировать на наличие дубликатов.
Нажмите Enter, чтоб окончить формулу. Двойные строчки показываются.
Отыскать дубликаты в Гугл Sheets при помощи дополнения
Вы также сможете применять надстройку Гугл для поиска и выделения дубликатов в Гугл Sheets. Эти дополнения дозволят для вас созодать больше с вашими дубликатами, к примеру, идентифицировать и удалять их; сопоставить данные по листам; игнорировать строчки заголовка; автоматическое копирование либо перемещение неповторимых данных в другое пространство; и наиболее.
Если для вас нужно разрешить всякую из этих ситуаций либо если ваш набор данных наиболее надежен, чем три столбца, разглядите возможность использования 1-го из последующих дополнений.
Каждое из этих дополнений ведет себя незначительно по-разному, но они все разрешают для вас отыскивать и выделять дублирующиеся данные, копировать дублирующиеся данные в другое пространство и удалять дублирующиеся значения либо удалять дублирующиеся строчки.
Как выделить дубликаты в Гугл Sheets

Хотя в Гугл Таблицах нет таковой же глубины функций, как в Microsoft Excel, у их все таки есть ряд нужных трюков. Одна из самых нужных функций — условное форматирование.
Это дозволяет для вас изменять форматирование всех ячеек, которые подчиняются определенному набору критерий, которые вы создаете.
Вы сможете, к примеру, выделить все ячейки, которые находятся над определенным значением либо содержат определенное слово. Условное форматирование имеет ряд применений, таковых как выделение ошибок либо сопоставление данных.
Очередное полезное применение условного форматирования — выделение дубликатов. Это дозволяет стремительно найти хоть какой циклический текст либо значения в большенный электрической таблице. Ах так это делается.
Выделение дубликатов из 1-го столбца
Если вы желаете выделить дубликаты из 1-го столбца в Гугл Таблицах, для вас необходимо поначалу избрать столбец, в котором вы желаете отыскать дубликаты.

Выделив столбец, нажмите « Формат»> «Условное форматирование» в строке меню.

Если в этом столбце уже активировано условное форматирование, щелкните Добавить другое правило. В неприятном случае вы сможете отредактировать правило, которое отображается в данный момент.

Нажмите поле « Формат ячеек, если» и изберите « Пользовательская формула» в раскрывающемся перечне.

Введите = countif (A: A, A1)> 1 в поле Значение либо формула либо поменяйте все вхождения буковкы A в формуле избранным столбцом.
К примеру, чтоб применить форматирование к столбцу M, ваша формула будет иметь вид = countif (M: M, M1)> 1.
Вы сможете установить стиль форматирования без помощи других, выбрав характеристики цвета и шрифта. Вы также сможете применять один из разных предустановленных стилей форматирования, кликнув текст по умолчанию в параметрах стиля форматирования , а потом выбрав один из предустановок.
Кликните Готово, чтоб добавить правило условного форматирования. Все повторяющиеся ячейки должны сейчас отображаться с избранным выделением.
Выделение дубликатов из нескольких столбцов
Это форматирование можно применить к нескольким столбцам, выделив любые дубликаты, которые возникают в избранном спектре ячеек.
Для начала изберите столбцы, которые вы желаете включить, удерживайте нажатой кнопку Ctrl , потом щелкните буковку вверху всякого столбца, чтоб добавить отдельные столбцы.
Вы также сможете, удерживая нажатой кнопку Shift, щелкнуть первую и последнюю ячейки в собственном спектре, чтоб избрать сходу несколько столбцов.

Выделив ячейки, нажмите « Формат»> «Условное форматирование».

Отредактируйте текущее правило либо нажмите Добавить другое правило, чтоб добавить новое правило.

Нажмите параметр « Форматировать ячейки, если…» и изберите « Пользовательская формула».

Введите = COUNTIFS ($ A $ 1: Z, A1)> 1 в поле Значение либо формула . Поменяйте любой A буковкой первого столбца в вашем выборе, а Z — крайним столбцом в вашем выборе.
К примеру, если ваши данные были в столбцах с M по Q , то правильной формулой будет = COUNTIFS ($ M $ 1: Q, M1)> 1 .
Вы сможете избрать собственный свой стиль форматирования в разделе « Стиль форматирования » либо кликнуть текст по умолчанию, чтоб применить один из тех предустановленных характеристик форматирования.
Кликните Готово, чтоб подтвердить и сохранить правило — ваши дубликаты сейчас будут выделены во всех избранных вами столбцах.
Любые пропущенные столбцы не будут выделены, но все равно будут учитываться при подсчете количества дубликатов.

Внедрение массивных функций Гугл Таблиц
Условное форматирование — это нужная функция, которая дозволяет просто отыскивать повторяющуюся информацию в большенный электрической таблице, но есть огромное количество остальных функций, которые могут быть неописуемо полезны для начинающих и обыденных юзеров Гугл Таблиц .
Вы сможете, к примеру, добавить в свои электрические таблицы проверку в ячейке, чтоб сделать лучше свойство ваших данных. Если вы желаете создавать автоматические задачки, вы сможете применять Гугл Таблицы для отправки электрических писем на базе значений ячеек .