Примеры функции ДЛСТР для подсчета количества знаков в Excel
Функция ДЛСТР делает возвращение количество символов в текстовой строке. Другими словами, автоматом описывает длину строчки, автоматом подсчитав количество знаков, которые содержит начальная строчка.
Описание механизма работы функции ФИШЕР в Excel
Почаще всего данная функция употребляется в связке с иными функциями, но бывают и исключения. При работе с данной функцией нужно задать длину текста. Функция ДЛСТР возвращает количество символов с учетом пробелов. Принципиальным моментом является тот факт, что данная функция быть может доступна не на всех языках.
Разглядим применение данной функции на определенных примерах.
Пример 1. Используя программку Excel, найти длину фразы «Хороший денек, класс. Я ваш новейший учитель.».
Для решения данной задачки открываем Excel, в случайной ячейке вводим фразу, длину которой нужно найти, далее избираем функцию ДЛСТР. В качестве текста избираем ячейку с начальной фразой и контролируем приобретенный итог (см. набросок 1).
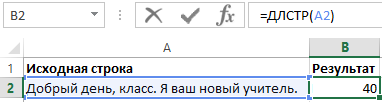
Набросок 1 – Пример расчетов.
Обычный пересчет знаков данной фразы (с учетом применяемых пробелов) дозволяет убедиться в правильности работы применяемой функции.
Формула с текстовыми функциями ДЛСТР ПРАВСИМВ и ПОИСК
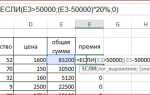
Пример 2. Имеется строчка, содержащая последующую название файла с его расширением: «Изменение.xlsx». Нужно произвести отделение исходной части строчки с именованием файла (до точки) без расширения .xlsx.
Для решения схожей задачки нужно выполнить последующие деяния. В Excel в случайной строке ввести начальные данные, опосля чего же нужно в хоть какой вольной ячейке набрать последующую формулу с функциями:
- ПРАВСИМВ – функция, которая возвращает данное число крайних символов текстовой строчки;
- ПОИСК – функция, находящая 1-ое вхождение одной текстовой строчки в иной и возвращающая исходную позицию отысканной строчки.
Приобретенные результаты проиллюстрированы на рисунке 2.

Набросок 2 – Итог выведения.
Логическая формула для функции ДЛСТР в условном форматировании
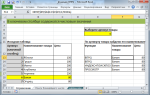
Пример 3. Посреди имеющегося набора текстовых данных в таблице Excel нужно выполнить выделение тех ячеек, количество знаков в которых превосходит 12.
Начальные данные приведены в таблице 1:
| Начальная строчка |
| Хороший денек, класс. Я ваш новейший ученик |
| Хороший денек, класс. |
| Хороший денек |
| Я ваш учитель |
| Я ваш |
Решение данной задачки делается методом сотворения правила условного форматирования. На вкладке «Основная» в блоке инструментов «Стили» избираем «Условное форматирование», в выпадающем меню указываем на опцию «Сделать правило» (вид окна показан на рисунке 3).
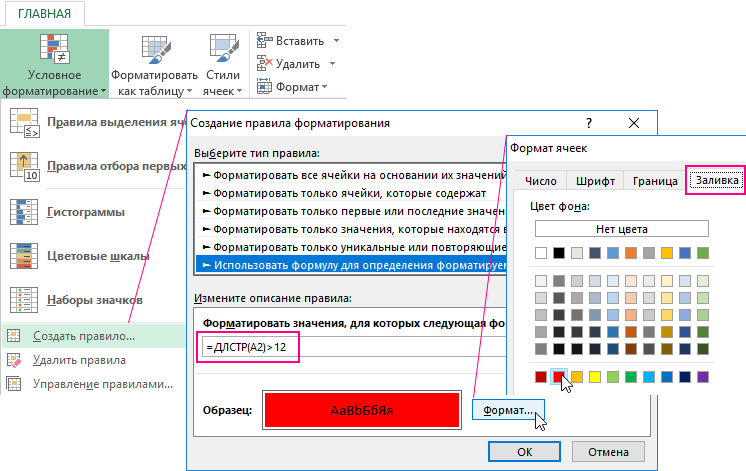
Набросок 3 – Вид окна «Сделать правило».
В окне в блоке «Изберите тип правила» избираем «Употреблять формулу для определения форматируемых ячеек», в последующем поле вводим формулу: =ДЛСТР(A2)>12, опосля чего же жмем клавишу формат и задаем нужный нам формат избранных полей. Приблизительный вид опосля наполнения данного окна показан выше на рисунке.
Опосля этого жмем на клавишу «Ок» и перебегаем в окно «Диспетчер правил условного форматирования» (набросок 4).
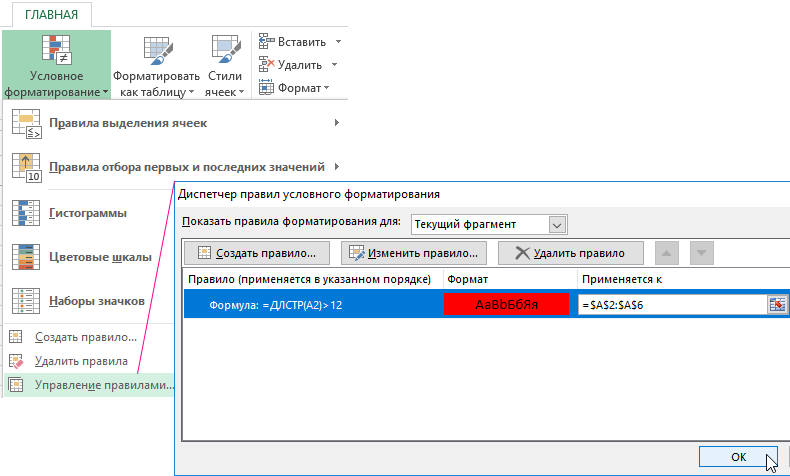
Набросок 4 – Вид окна «Диспетчер правил условного форматирования».
В столбце «Применяется к» задаем нужный нам спектр ячеек с начальными данными таблицы и жмем клавишу «Ок». Приобретенный итог приведен на рисунке 5.
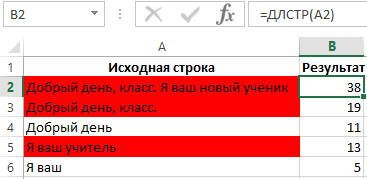
Набросок 5 – Окончательный итог.
Функция ДЛСТР интенсивно употребляется в формулах Excel при композиции с иными текстовыми функциями для решения наиболее сложных задач. К примеру, при подсчете количества слов либо знаков в ячейке и т.п.
Расширенные способности Microsoft Excel с примерами и описанием функций
Место снутри программки похоже на лист бумаги с клеточками. Любая колонка тут имеет свое заглавие – по буковке алфавита, а любая строчка – собственный номер. У каждой ячейки есть собственный адресок, который состоит из сочетания буковкы столбца и номера строчки – к примеру, ячейка А1 либо B2 – это кое-чем похоже на игру в Морской бой. Сам файл похож на книжку со обилием листов. Нажимая на символ плюса в левом нижнем углу странички, можно создавать новейшие листы, и к примеру, помещать любой набор данных на отдельный лист.
Импорт данных
Excel работает с разными форматами данных. Часто встречающееся расширение табличного файла – это xlsx, в котором Excel по дефлоту сохраняет данные. Чтоб открыть файл в этом формате, нужно надавить «Файл» – «Открыть» – и указать путь к файлу.
Очередное распространенное расширение – csv. Это текстовый файл, значения в котором разбиты особыми знаками – к примеру, запятыми (отсюда и заглавие – comma-separated values) либо иными. Его можно открыть в обыкновенном Блокноте. Там можно поглядеть содержимое файла, но чтоб обрабатывать такие данные, понадобится Excel. Чтоб открыть csv, нужно надавить «Файл» – «Импортировать» – и указать путь к файлу.
Опосля загрузки покажется меню с разделом «Тип разделителя». Обычно Гугл Sheets сами определяют верный тип разделителя, потому галочку можно бросить на функции «Определять автоматом». Если же тип разделителя определен ошибочно, и заместо табличного представления вы получили данные в нечитаемом виде, можно указать тип разделителя без помощи других. Избрать из предложенных опций либо вставить собственный знак в окно «Иной». Потом надавить «Импортировать данные» и «Открыть на данный момент».
Подготовительная работа с данными
Когда данные загружены, сперва стоит проверить, в комфортном ли для работе виде они представлены. Принципиально, к примеру, проверить, есть ли у столбцов (а время от времени и строк) наименования, это упростит работу с данными.
Данные снутри ячеек в Excel представлены в различных форматах – в нашем примере это даты, текст либо числа. Все виды форматов, с которыми работает программка, можно узреть во вкладке меню «Формат». Перед работой с данными, стоит оценить, правильно ли распознан их формат. К примеру, если числам придать формат текста, с ними недозволено будет создавать вычисления. Поменять их можно в том же разделе меню «Формат».
Потом принципиально оценить, хватает ли данных либо их стоит конвертировать для предстоящего анализа. Разглядим на нашем примере. В наборе данных с количеством новейших веб-сайтов по продаже мед масок есть столбец с количеством веб-сайтов в зоне «.рф», и столбец с количеством веб-сайтов в зоне «.ru». Нас интересует полное количество веб-сайтов в обеих зонах. Можно добавить очередной столбец, отдать ему заглавие «.рф и .ru» и без помощи других заполнить. Сложить значения из 2-ух столбцов («.рф» и «.ru») нам поможет формула.
Функции кубов и сводные таблицы
Более обычным и в тоже время весьма массивным средством представления данных являются сводные таблицы . Они могут быть построены на базе данных, содержащихся: а) на листе Excel, б) кубе OLAP либо в) модели данных Power Pivot. В крайних 2-ух вариантах, кроме сводной таблицы, можно применять аналитические функции (функции кубов) для формирования отчета на листе Excel. Сводные таблицы проще. Функции кубов труднее, но предоставляют больше гибкости, в особенности в оформлении отчетов, потому они обширно используются в дашбордах.
Предстоящее изложение относится к формулам кубов и сводным таблицам на базе модели Power Pivot и в нескольких вариантах на базе кубов OLAP.
Обычный метод получить функции кубов
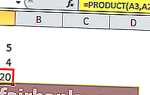
Когда (если) вы начинали учить код VBA, то узнали, что проще всего получить код, используя запись макроса. Дальше код можно редактировать, добавить циклы, проверки и др. Аналогично проще всего получить набор функций кубов, преобразовав сводную таблицу (рис. 2). Встаньте на всякую ячейку сводной таблицы, перейдите на вкладку Анализ, кликните на кнопочке Средства OLAP, и нажмите Конвертировать в формулы.

Рис. 2. Преобразование сводной таблицы в набор функций куба
Числа сохранятся, при этом это будут не значения, а формулы, которые извлекают данные из модели данных Power Pivot (рис. 3). Получившуюся таблицу вы может отформатировать. В том числе, можно удалять и вставлять строчки и столбцы вовнутрь таблицы. Срез остался, и он влияет на данные в таблице. При обновлении начальных данных числа в таблице также обновятся.

Рис. 3. Таблица на базе формул кубов
Функция КУБЗНАЧЕНИЕ()
Это, пожалуй, основная функция кубов. Она эквивалента области Значения сводной таблицы. КУБЗНАЧЕНИЕ извлекает данные из куба либо модели Power Pivot, и отражает их вне сводной таблицы. Это значит, что вы не ограничены пределами сводной таблицы и сможете создавать отчеты с бессчетными способностями.
Написание формулы «с нуля»
Для вас не непременно преобразовывать готовую сводную таблицу. Вы сможете написать всякую формулу куба «с нуля». К примеру, в ячейку С10 введена последующая формула (рис. 4):
Большие и строчные буковкы в Excel
Не глядя на то, что Excel – табличный редактор и в первую очередь предназначен для работы с числовыми значениями, набор инструментов в нем для преобразования текстовых значений довольно разнообразен. Задачки по изменению больших букв на буковкы строчные и назад могут быть решены различными методами.
Текстовые функции
Текстовых функций в Excel немногим больше 20, но используя их сочетания, можно произвести с текстом фактически любые преобразования. Все текстовые функции можно отыскать на вкладке «Формулы», в группе клавиш «Библиотека функций», в меню клавиши «Текстовые». Также Вы сможете ознакомиться с коротким описанием этих функций.
Как конвертировать строчные буковкы в строчные?
КАК СДЕЛАТЬ ВСЕ БУКВЫ ПРОПИСНЫМИ
С помощью обычной функции Excel «ПРОПИСН» можно все буковкы в строке перевести в верхний регистр (создать большими).
Как Создать Все 1-ые Буковкы Строчными
Обычная функция Excel «ПРОПНАЧ» изменяет 1-ые буковкы в любом слове со строчных на большие.
Как создать 1-ые буковкы строчными
Композиция интегрированных в Excel функций «ПРОПИСН», «СЦЕПИТЬ», «ЛЕВСИМВ», «ПРАВСИМВ» и «ДЛСТР» дозволяет привести лишь 1-ые буковкы к верхнему регистру.
Итоговая формула имеет вид «=СЦЕПИТЬ(ПРОПИСН(ЛЕВСИМВ(B2));ПРАВСИМВ(B2;ДЛСТР(B2)-1))», где B2 – это адресок ячейки с текстовым значением.
Как перевоплотить большие буковкы в строчные?
как создать все буковкы строчными
«СТРОЧН» из набора интегрированных текстовых функций преобразует все буковкы в строчные.
кАК СДЕЛАТЬ ПЕРВЫЕ БУКВЫ СТРОЧНЫМИ
В неких вариантах нужно создать строчной лишь первую буковку.
«=СЦЕПИТЬ(СТРОЧН(ЛЕВСИМВ(B2));ПРАВСИМВ(B2;ДЛСТР(B2)-1))», где B2 – это адресок ячейки с начальным значением.
Внедрение сочетаний функций просит издержек времени, делает формулы массивными, понижает их восприятие и эффективность использования.
Пользовательские функции
Как поменять регистр букв на обратный?
Чтоб привести буковкы нижнего регистра к верхнему, а буковкы верхнего регистра к нижнему обычными функциями Excel, придется серьезно потрудиться. Такового результата тяжело достигнуть даже композицией обычных функций, потому что требуется повторяющийся перебор всех знаков.
Итог, который трудно получить обычными функциями Excel, довольно просто быть может достигнут с помощью функций пользовательских. Ниже приведен листинг пользовательской функции, написанной на Visual Basic for Application.

Эту функцию можно применять, скопировав программный код в личную книжку макросов. Также, можно безвозмездно скачать надстройку и установить её по аннотации. Опосля установки надстройки функция будет добавлена в раздел «Пользовательские функции».
Готовое решение для стремительных преобразований текста
Как видно из вышеприведенных примеров, с помощью функций можно достигнуть фактически всех результатов, но все это делается не так стремительно как хотелось бы. К примеру, в Word подобные задачки решаются в два-три клика мыши с помощью функции «Регистр», меню которой вызывается клавишей, комфортно расположенной на вкладке «Основная».
Упростить решение задач связанных с конфигурацией текстовых значений, убыстрить обработку данных и при всем этом избежать ввода формул помогает функциональная надстройка для Excel, изображение диалогового окна которой приведено ниже.
 Для получения результата довольно всего-лишь задать спектр ячеек и избрать из выпадающего перечня подходящую функцию. Значения выделенных ячеек сходу заменяются плодами вычисления избранной функции.
Для получения результата довольно всего-лишь задать спектр ячеек и избрать из выпадающего перечня подходящую функцию. Значения выделенных ячеек сходу заменяются плодами вычисления избранной функции.

Надстройка дозволяет работать как с выделенным спектром ячеек, так и с применяемым спектром. Не считая задач рассмотренных выше, надстройка дозволяет переставлять буковкы в оборотном порядке, также удалять непечатаемые знаки и излишние пробелы, которые могут появляться при использовании текстовых функций.
Str Python. Строчки в Python
 Базы
Базы
Одним из самых распространённых типов данных является строковый. Вопреки расхожему воззрению, программер почаще сталкивается не с числами, а с текстом. В Python, как понятно, всё является объектами. Не исключение и строчки – это объекты, состоящие из набора знаков. Естественно, в языке существует широкий набор инструментов для работы с сиим типом данных.
Строковые операторы
Операторы «+» и «*» в Питоне применимы не только лишь к числам, да и к строчкам.
Оператор сложения строк +
Оператор «+» делает операцию, именуемую конкатенацией, — объединение строк.
Оператор умножения строк *
Оператор «*» дублирует строчку обозначенное количество раз.
Это работает лишь с целочисленными множителями. Если помножить на ноль либо отрицательное число, результатом будет пустая строчка. Но лучше так не созодать.
Оператор принадлежности подстроки in
Если нужно проверить, содержится ли подстрока в строке, комфортно воспользоваться оператором “in”
Так же можно применять этот оператор с «not» для инвертирования результата.
Интегрированные функции строк в python
Пайтон содержит ряд комфортных интегрированных функций для работы со строчками.
Функция ord() возвращает числовое значение знака, при чём, как для шифровки ASCII, так и для UNICODE.
Функция chr(n) возвращает символьное значение для данного целого числа, другими словами делает действие оборотное ord().
Функция len() возвращает количество знаков в строке.
Функция str() возвращает строковое представление объекта.
Индексация строк
Строчка является упорядоченной последовательностью знаков. Иными словами, она состоит из знаков, стоящих в определённом порядке. Благодаря этому, к символу можно обратиться по его порядковому номеру. Для этого нужно указать номер знака в квадратных скобках. Нумерация начинается с нуля (0 – это 1-ый знак).
Попытка воззвания по индексу большему чем длина строчки вызовет исключение IndexError:
В качестве индекса быть может применено отрицательное число. В этом случае индексирование начинается с конца строчки: -1 относится к крайнему символу, -2 к предпоследнему и так дальше.
Срезы строк
В Python существует механизм срезов коллекций. Срезы разрешают обратиться к подстроке используя индексы. Для этого нужно в квадратных скобках указать: [начальный индекс : конечный индекс : шаг]. Любой из характеристик является необязательным. Так как строчка это коллекция, срезы применимы и к ней.
Форматирование строчки
В Python есть функция форматирования строчки, которая официально названа литералом отформатированной строчки, но обычно упоминается как f-string.
Главной индивидуальностью данной функции является возможность подстановки значения переменной в строчку.
Чтоб это создать при помощи f-строки нужно:
- Указать f либо F перед кавычками строчки (что скажет интерпретатору, что это f-строка).
- В любом месте снутри строчки вставить имя переменной в фигурных скобках (< >).
Изменение строк
Тип данных строчка в Python относится к неизменяемым (immutable), но это практически не влияет на удобство их использования, ведь можно сделать изменённую копию. Для этого есть два вероятных пути:
- Употреблять перезапись значения переменной
- Употреблять интегрированный способ replace(x, y):
Как Вы сможете созидать, данный способ не меняет строчку, а возвращает изменённую копию.
Интегрированные способы строк в Python
Так как строчка в Пайтон – это объект, у него есть свои способы. Способы – это те же самые функции, просто они «закреплены» за объектами определённого класса.
Изменение регистра строчки
Если Для вас нужно поменять регистр строчки, комфортно применять один из последующих способов
capitalize() переводит первую буковку строчки в верхний регистр, другие в нижний.
Не алфавитные знаки не меняются:
lower() конвертирует все буквенные знаки в строчные.
swapcase() меняет регистр на обратный.
title() конвертирует 1-ые буковкы всех слов в большие
upper() конвертирует все буквенные знаки в большие.
Отыскать и поменять подстроку в строке
Эти способы предоставляют разные методы поиска в мотивированной строке обозначенной подстроки.
Любой способ в данной группе поддерживает необязательные аргументы start и end. Они задают спектр поиска: действие способа ограничено частью мотивированной строчки, начинающейся в позиции знака start и продолжающейся прямо до позиции знака end, но не включая его. Если start обозначено, а end нет, способ применяется к части строчки от start до конца.
count() подсчитывает количество четких вхождений подстроки в строчку.
endswith() описывает, завершается ли строчка данной подстрокой.
find() отыскивает в строке заданную подстроку. Возвращает 1-ый индекс который соответствует началу подстроки. Если обозначенная подстрока не найдена, возвращает -1.
index() отыскивает в строке заданную подстроку.
Этот способ схож find(), кроме того, что он вызывает исключение ValueError, если подстрока не найдена.
rfind() отыскивает в строке заданную подстроку, начиная с конца.
Возвращает индекс крайнего вхождения подстроки, который соответствует её началу.
rindex() отыскивает в строке заданную подстроку, начиная с конца.
Этот способ схож rfind(), кроме того, что он вызывает исключение ValueError, если подстрока не найдена.
startswith() описывает, начинается ли строчка с данной подстроки.
Систематизация строк
Способы в данной группе систематизируют строчку на базе знаков, которые она содержит.
isalnum() возвращает True, если строчка не пустая, а все ее знаки буквенно-цифровые (или буковка, или цифра).
isalpha() описывает, состоит ли строчка лишь из букв.
isdigit() описывает, состоит ли строчка из цифр.
isidentifier() описывает, является ли строчка допустимым идентификатором (заглавие переменной, функции, класса и т.д.) Python.
isidentifier() возвратит True для строчки, которая соответствует зарезервированному главному слову Пайтон, даже если его недозволено применять.
Вы сможете проверить, является ли строчка главным словом Python, используя функцию iskeyword(), которая находится в модуле keyword.
Если вы вправду желаете убедиться, что строчку можно применять как идентификатор Питон, вы должны проверить, что isidentifier() = True и iskeyword() = False.
islower() описывает, являются ли буквенные знаки строчки строчными.
isprintable() описывает, состоит ли строчка лишь из печатаемых знаков.
Это единственный способ данной группы, который возвращает True, если строчка не содержит знаков. Все другие ворачиваются False.
isspace() описывает, состоит ли строчка лишь из пробельных знаков.
Тем не наименее есть несколько знаков ASCII, которые числятся пробелами. И если учесть знаки Юникода, их еще более:
‘f’ и ‘r’ являются escape-последовательностями для знаков ASCII; ‘u2005’ это escape-последовательность для Unicode.
istitle() описывает, начинаются ли слова строчки с большей буковкы.
isupper() описывает, являются ли буквенные знаки строчки большими.
Сглаживание строк, отступы
Способы из данной группы управляют отображением строчки.
center() сглаживает строчку по центру.
Если указан необязательный аргумент fill, он употребляется как знак наполнения:
Если строчка больше либо равна обозначенной ширине, строчка ворачивается без конфигураций:
expandtabs() подменяет любой знак табуляции (‘t’) пробелами. По дефлоту табуляция заменяются на 8 пробелов.
tabsize необязательный параметр, задающий количество пробелов.
ljust() сглаживание по левому краю.
lstrip() удаляет переданные в качестве аргумента знаки слева. По дефлоту это пробелы.
replace() подменяет вхождения подстроки в строке.
Необязательный аргумент count, показывает количество замен, которое необходимо выполнить:
rjust() сглаживание по правому краю строчки в поле.
rstrip() обрезает пробельные знаки.
strip() удаляет знаки с левого и правого края строчки.
Когда возвращаемое значение способа является иной строчкой, как это нередко бывает, способы можно вызывать поочередно:
zfill() возвращает копию строчки дополненную нулями слева для заслуги длины строчки обозначенной в параметре width:
Если строчка короче либо равна параметру width, строчка ворачивается без конфигураций:
Способы преобразование строчки в перечень
Способы в данной группе превращают строчку в иной тип данных и напротив. Эти способы возвращают либо принимают коллекции (почаще всего это перечень).
join() возвращает строчку, которая является результатом конкатенации частей коллекции и разделителя.
Стоит направить внимание что все элементы итерируемого объекта должны быть строкового типа. Так же Вы могли увидеть в крайнем примере, что для объединения словаря в строчку способ join() употребляет не значения, а ключи. Если Для вас необходимы конкретно ключи, то делается это так:
Труднее ситуация, когда необходимы пары ключ-значение. Тут придётся сначала распаковать кортежи.
partition() разделяет строчку на базе разделителя (действие, оборотное join). Возвращаемое значение представляет собой кортеж из 3-х частей:
- Часть строчки до разделителя
- Разделитель
- Часть строчки опосля разделителя
Если разделитель не найден, возвращаемый кортеж содержит строчку и ещё две пустые строчки:
rpartition() разделяет строчку на базе разделителя, начиная с конца.
rsplit() разделяет строчку на перечень из подстрок. По дефлоту разделителем является пробел.
split() разделяет строчку на перечень из подстрок.
Ведет себя как rsplit(), кроме того, что при указании maxsplit – наибольшего количества разбиений, деление начинается с левого края строчки:
Если параметр maxsplit не указан, меж rsplit() и split() различия нет.
splitlines() разделяет текст на перечень строк и возвращает их в перечне. Хоть какой из последующих знаков либо последовательностей знаков считается границей строчки:
| Разделитель | Значение |
| n | Новенькая строчка |
| r | Возврат каретки |
| rn | Возврат каретки + перевод строчки |
| v либо же x0b | Таблицы строк |
| f либо же x0c | Подача формы |
| x1c | Разделитель файлов |
| x1d | Разделитель групп |
| x1e | Разделитель записей |
| x85 | Последующая строчка |
| u2028 | Новенькая строчка (Unicode) |
| u2029 | Новейший абзац (Unicode) |
Заключение
В этом уроке мы разглядели главные инструменты для работы со строчками в Python. Видите ли, они комфортны и гибки. Есть интегрированные функции и способы объекта «строчка», строковые литералы. Ещё больше способностей даёт нерассмотренный в этом уроке способ format и модуль re. Так же отдельного разговора заслуживает работа с шифровками. Необходимо подчеркнуть для тех, кто уже знаком с иными языками программирования: в отличие от неких из их, один знак в Пайтоне тоже является строчкой. И изюминка в итоге. Так как в Питоне всё является объектом, у каждой строчки тоже есть атрибуты.