
7 сервисов для визуализации данных: не привлекая дизайнеров и программистов
Аналитики OWOX BI собрали перечень более фаворитных и комфортных сервисов, которые посодействуют рекламщикам визуализировать данные.
Раз в день команды рекламных отделов получают массивы данных из соц сетей, Гугл Analytics, CRM и остальных источников, которые нужно обработать и конвертировать в прекрасный и понятный отчет. Почти все сервисы разрешают без помощи программера создавать понятные интерактивные дашборды под свои задачки, создавать шаблоны и отправлять отчетность в виде ссылки по электрической почте.
Гугл Data Studio
Простой бесплатный сервис визуализации данных, который дозволяет стремительно сводить, рассматривать и визуализировать данные в интерактивной панели управления.
Формат данных. Сервис поддерживает выше 17 собственных коннекторов и наиболее сотки различных источников баз данных партнеров. К примеру, Гугл Реклама, Гугл Таблицы, Cloud SQL, MySQL, Гугл Sheets, Search Console, YouTube Analytics, Facebook Ads, Instagram, Гугл Analytics, Yandex.Метрика, Yandex.Директ, файл CSV, PostgreSQL, Adwords API, Attribution 360 и остальные.
Плюсы. Сервис бесплатный и интуитивный. Не надо иметь глубочайшее осознание синтаксиса программирования, чтоб применять сервис. Отлично встраивается с продуктами Гугл. Есть возможность настраивать собственные шаблоны.
Сервис повсевременно обновляется. В январе возникла возможность настраивать просмотр и публикацию отчетов, созидать конфигурации в источниках данных и отчетах, поделиться недлинной ссылкой и запланировать рассылку избранным юзерам по имейлу.
Минусы. Маленькой набор зрительных инструментов, способности для работы с вычисляемыми полями ограничены, по сопоставлению с иными пользующимися популярностью сервисами визуализации (Tableau, Spreadsheets, Power BI, QlikView). Некие коннекторы партнеров стают платными, если превысить предел данных либо время их использования.

Power BI
Бесплатная всеохватывающая BI-платформа от Microsoft, с помощью которой можно стремительно обрабатывать данные для принятия взвешенных решений. Платформа бизнес-аналитики соединяет воединыжды несколько товаров, один из которых помогает визуализированные отчеты, рассматривать данные и верно оценивать рекламные характеристики. Сервис позволять строить детализированные и общие отчеты под запросы управляющего отдела рекламы, маркетолога либо аналитика. Существует корпоративная платная версия Power BI Pro с наиболее широкими способностями: $9,99 за месяц за юзера.
Формат данных. Данные можно загружать из различных источников: файлов различных форматов, более узнаваемых баз данных, баз Microsoft и Гугл, веба, CRM-систем и т.д.
Плюсы. Помогает соединять воединыжды и ассоциировать данные из различных источников. Прекрасные галереи визуализации. Весьма комфортен для тех, кто привык работать с таблицами Excel. Отлично работает с иными продуктами Microsoft (Azure Cloud Service, SQL Server). Содержит большенный набор инструментов визуализации для сотворения различных отчетов. Существует десктопная и пасмурная версия интерфейса. Больше способностей, чем в Гугл Data Studio. Есть возможность интеграции BI в собственные приложения для визуализации. Интуитивный интерфейс.
Минусы. Есть трудности в работе с большенными данными, также с обработкой аналитических данных товаров Гугл и Yandex. Для более корректного подключения источников данных есть кастомные коннекторы. Сервисы выгрузки данных, к примеру, бесплатный Geneport, помогают рассматривать данные и создавать отчет в Power BI. Не хватает инструментов обработки и чистки данных.


Tableau
Наикрупнейшая и очень облегченная для юзера платформа, специализирующаяся на анализе и визуализации данных. Дозволяет строить эффектную графику. Основное отличие от соперников — возможность соединять воединыжды данные из различных источников. Есть бесплатная и платная версия.
Формат данных. Работает с несколькими десятками источников данных в формате файлов, баз данных и пасмурных систем: XML, MS Excel, MySQL, SQL, Гугл BigQuery, Microsoft Azure и т.д.
Плюсы. Объединение данных из различных источников. Возможность одновременной работы команды из нескольких человек в режиме настоящего времени. Как и в Power BI, есть возможность пересылать отчеты по электрической почте, публиковать ссылку на сервере и получать доступ к отчету по ссылке. Гибкий интерфейс панели управления, позволяющий кооперировать и накладывать друг на друга нужные элементы, прекрасная и различная галерея графики. С обслуживанием сумеют работать даже новенькие: легкий и понятный интерфейс. Надежная служба саппорта и огромное проф общество юзеров.
Минусы. Всю функциональность можно получить лишь за плату. Бесплатна лишь общественная версия сервиса. Desctop Personal — $35 в мес/юзера, Desctop Professional — $70 в мес/юзера, Server — $35 в мес/юзера, Tableau Online $42 в мес/юзера с полной поддержкой. Есть корпоративный пакет с регламентированным числом источников данных $999–1999 в год. Данные необходимо за ранее обрабатывать. Просит консалтинга со стороны профильного ИТ-специалиста.

курс
Tableau: визуализация данных
Выяснить больше
- Перейдёте от вороха таблиц к понятным визуализациям
- Cможете без помощи других заниматься анализом данных и получите фундамент для внедрения бизнес-аналитики в компании
ChartBlocks
Обычное приложение для сотворения HTML5- диаграмм на базе разных данных, которые корректно показываются в любом браузере либо устройстве. Есть бесплатная и платная версии.
Формат данных. Вероятен импорт баз данных, электрических таблиц и прямых трансляций из всех источников.
Плюсы. Мастер диаграмм весьма прост в использовании; гибкие опции интерфейса разрешают поменять цвет, числа и шрифты. Сделанной диаграмму можно встраивать в сайт и делиться ссылкой. Приложение повсевременно обновляется, анонсировано внедрение источника потока {живых} данных. Диаграммы реагируют на любые устройства и размеры экранов, просто масштабируются, отлично считываются с мониторов. Полученную картину можно выводить на высококачественную печать. Можно встраивать интерактивную диаграмму в Facebook и Twitter.
Минусы. Широкий диапазон функций доступен лишь при покупке 2-ух платных пакетов: «Проф» $20 за месяц — включает 500 000 просмотров и до 75 активных диаграмм, «Элитный» $65 за месяц — включает до 2,5 млн просмотров, до 200 активных диаграмм, доступ к API. Бесплатная версия предусмотрена для личного использования, вероятна опосля регистрации.

Plotly
Платформа для сотворения графиков, диаграмм, презентаций, датасетов и неповторимых дашбордов. Дозволяет загрузить данные, подобрать вижуал, настроить итог. Есть платная и бесплатная версии.
Формат данных. Вероятен импорт из таблиц Excel, баз MySQL, Redshift и остальных. Платформа работает с сервисами, написанными на языках программирования Python, JavaScript, Matlab, R.
Плюсы. Можно создавать визуализацию, в какой можно редактировать фактически все: легенду, подписи, толщину линий, цвет, размер. В галерее есть неповторимые диаграммы, которых нет в остальных сервисах. Можно создавать вижуал, сохранять его как векторную графику либо картину в формате png и встраивать на сайт в формате html-кода. Включает библиотеку зрительных инструментов с открытым кодом, которая дозволяет создавать огромное количество графиков, датасеты, также до 25 активных диаграмм. Однострочный код, позволяющий визуализировать не одну, а несколько диаграмм. Высочайшая детализация данных на графиках.
Минусы. Платная версия — $33 за месяц. Некие удобные трудности в работе сервиса, которые решаются через службу саппорта в Twitter.

Infogram
Один из более узнаваемых и простых инструментов визуализации данных. Дозволяет строить интерактивные диаграммы и графики. Есть несколько тарифных планов, один из которых бесплатный с самыми базисными функциями.
Формат данных. Импортировать данные можно из таблиц Excel, баз данных MySQL, PostgreSQL, Amazon Redcliff, Oracle, and Microsoft SQL Server, карты из веб, Гугл Maps, GIF-изображения из библиотеки Giphy.
Плюсы. Интуитивная панель управления, упрощающая работу с данными. Юзеру не надо владеть особыми познаниями. Автоматические пошаговые аннотации дают подсказку порядок действий. Возможность кастомизации имеющихся шаблонов. Создав вижуал, можно скопировать ссылку на страничку с графикой либо код для сайта. Есть возможность опубликовать инфографику в Twitter, Facebook либо Pinterest. Интерактивную графику можно сохранять в нескольких форматах на Гугл Drive либо в Dropbox. Сделанные шаблоны сохраняются в галерее и по мере необходимости в их можно обновлять данные и опять публиковать.
Минусы. Базисный бесплатный тариф имеет весьма умеренные способности. Другие тарифные планы — платные. Зависимо от способностей всякого плана стоимость пакета варьируется в границах $19–149 за месяц. Ограниченные способности в анализе и обработке данных. Не принимает кириллицу в работе с шрифтами. На всех сделанных работах находится логотип сервиса.

ЧИТАТЬ ТАКЖЕ

DataDeck
Дозволяет синхронизировать данные из различных сервисов и визуализировать в виде понятных дашбордов. Дает возможность производить веб-анализ, к примеру, выслеживать конверсию, время на веб-сайте, главные слова, проводить сегментацию аудитории и другое. Все принципиальные характеристики рекламщик лицезреет на понятном дашборде в настоящем времени.
Формат данных. Сервис встраивается с Excel, Slack, Гугл Analytics, MailChimp, Гугл AdWords, Гугл AdSense, Гугл Drive, Facebook, MySQL, MS SQL Server, Amazon S3 и неких остальных. Есть бесплатная пробная версия, бесплатный и платный помесячный тариф и платная лицензия, стоимость которой оговаривается персонально.
Плюсы. Интуитивный и легкий для осознания интерфейс. Отчеты можно создавать стремительно и просто, используя готовые шаблоны. Над отчетом в одном дашборде могут работать несколько человек в режиме настоящего времени. Ведется неизменное обновление способностей сервиса. Дешевле аналогов вроде Tableau.
Минусы. Есть лишь главные источники данных и маленькое число частей для визуализации. Нереально применять результаты SQL-запросов. Отсутствуют вычисляемые поля. Большей функциональностью владеют платные версии — $29 за месяц за юзера и платная бессрочная лицензия.
Массивы в php
Как писалось выше, массив состоит из частей, любой из которых имеет ключ и значение. К примеру массив содержащий информацию о ценах в ресторанном меню может смотреться так:
| Ключ | Значение |
|---|---|
| breakfast | 700 |
| dinner | 1500 |
| supper | 1100 |
Массив может иметь лишь один элемент с данным ключом, т.е. в приведённом выше массиве не быть может 2-ух частей с ключом dinner . При попытке «добавить» 2-ой dinner , мы просто перезапишем значение уже имеющегося элемента. В данном примере мы разглядели более нередкий вариант организации массива, а конкретно в виде ассоциативного. Ассоциативный массив удобнее применять в коде, т.к. его ключи имеют осмысленные наименования (ассоциируются с какими-то частями приложения либо данными которые обрабатывает скрипт). Но есть наиболее обычной пример массив, это числовые массивы. При их разработке не надо указывать ключ, он задаётся автоматом в виде целого числа, начиная с нуля.
| Ключ | Значение |
|---|---|
| 0 | 700 |
| 1 | 1500 |
| 2 | 1100 |
Разглядим пример:
В первом случае элементы массива представляют из себя пару ключ-значение, где в качестве ключа употребляются строковые наименования «блюд» (приёмов еды по сути, но пусть будет блюд), а значение это стоимость блюда. Во 2-м же случае я указал лишь цены, при всем этом интерпретатор PHP автоматом проставит ключи элементам массива.
Операции с массивами
Один из случаев главный операции с массивами, а конкретно его создание мы разглядели выше. Как ещё можно сделать массив? Самый обычной вариант, это создание пустого массива:
Создание и модификация массива
Пустой массив может служить заготовкой под определённую коллекцию данных. Естественно его можно не определять заблаговременно и сделать прямо в цикле где он должен заполняться, но тогда это будет наименее понятный код.
Вы так же сможете заполнить массив на лету, к примеру данными из базы данных:
Перебор массивов
С иной стороны готовый массив можно перебрать и к примеру вывести его элементы на экран:
Совершенно в php существует больше 70 функций для работы с массивами, но почти всегда вы будет применять не больше 20. Приведу некие из их:
- in_array — инспектирует присутствие элемента в массиве
- key_exists — инспектирует находится ли в массиве обозначенный ключ либо индекс
- array_search — производит поиск данного значения в массиве и возвращает ключ первого отысканного значения
- array_merge — соединяет воединыжды 2 и наиболее массивов в один
- array_chunk — разбивает массив на части
Сортировка массива
Отдельным блоком может идти операции связанные с сортировкой массив. В PHP существует несколько интегрированных функций для резвой сортировки массивов, к примеру по возрастанию/убыванию значения либо в алфавитном порядке. Причём сортировка может идти как по ключам массива так и по значениям. Одной из увлекательных способностей предоставляет функция usort() , с помощью которой вы сможете отсортировать элементы массива используя свой метод сопоставления. Разглядим пример:
В итоге выполнения данного примера получим таковой массив:
Как вы осознаете данный пример очень упрощён. Но снутри вашей функции compare() можно воплотить хоть какой метод сопоставления частей. Основное верно возвращать значение, ноль — если элементы не различаются и их не нужно поменять местами и 1 либо -1 если необходимо поменять порядок частей.
Вы так же сможете пробросить в тело функции compare() внешнюю переменную используя анонимную функцию и ключевое слово use :
Видите ли сейчас compare() воспринимает характеристики $params и возвращает анонимную функцию в какой уже реализован ваш метод сопоставления в каком употребляются переданные характеристики. Итог при таком методе поменяется:
Грубо говоря сортировка по возрастанию шла пока значение $a попадало в спектр от 0 до 3-х.
Глобальные массивы
В PHP начиная с версии 4 ввели таковой суть как «суперглобальные массивы». Это особенные переменные доступные в хоть какой части приложения и содержат информацию, к примеру о состоянии сервера (массив $_SERVER) сессии, куках либо переданных от юзера запросах, одним словом о состоянии среды выполнения приложения. Сейчас в PHP доступно девять суперглобальных массивов:
| Наименование | Описание массива |
| $GLOBALS | Этот массив содержим все переменные объявленные в скрипте, при всем этом имена переменных являются ключами этого массива. |
| $_SERVER | Данный массив содержит всю информацию о сервере, а так же опции среды в какой производится скрипт |
| $_GET | Массив переменных переданных PHP скрипту по средствам GET запроса (через адресную строчку браузера либо иными способами, к примеру curl()) |
| $_POST | Так же как и GET содержит переданные скрипту переменные, лишь уже способом POST |
| $_COOKIE | Содержим coockies-ы юзера |
| $_REQUEST | Соединяет воединыжды внутри себя массивы $GET, $POST и $COOKIE. Не рекомендуется применять, не неопасно, хотя и комфортно. |
| $_FILES | Содержим перечень файлов загружаемых на сервер через веб-формы (имя, временный путь, размеры и т.д.) |
| $_ENV | Содержит переменные окружения в каком запущен PHP скрипт |
| $_SESSION | В данном массиве содержаться все переменные сессии текущего юзера |
Многомерные массивы
Как вы уже понимаете, элементы массива могут содержать в качестве значения данные хоть какого типа, строчки, числа, логические, в том числе и остальные массивы. Массив состоящий из остальных массивов именуется многомерным либо вложенным массивом. На практике употребляется 2-3 уровня вложенности для хранения каких-то связанных структурных данных (к примеру данных о покупателях магазина либо каталоге продуктов), обработка массивов большей вложенности усложняется и употребляется редко.
Давайте разберёмся как создавать и вести взаимодействие с многомерными массивами.
Создание многомерных массивов
Сначала сделаем обычной двумерный массив служащих организации:
Массив $multilavelArray содержим внутри себя три остальных массива описывающих некие характеристики служащих, а конкретно имя, возраст и должность. Эти данные могли бы быть получены из БД либо сложной веб-формы.
Направьте внимание что в «родительском» массиве мы не указывали символьных ключей, потому массивам снутри были просто присвоены числовые индексы 0, 1, 2. Давайте сейчас распределим наших служащих по отделам и добавим ещё 1-го сотрудника.
Сейчас мы имеем многомерный массив в каком на «первом уровне» хранятся отделы компании, а уже снутри отделов сотрудники. При всем этом отдел имеет символьный ключ, к примеру DEPARTMENT_IT — отдел IT. Незначительно усложним наш пример и добавим информацию о наименовании отделов и времени работы, а служащих отдела поместим на уровень ниже:
Видите ли используя многомерные массивы можно строить достаточно сложные структуры данных с которыми в последствии предстоит работать нашему веб-приложению.
Доступ к элементам многомерного массива
Разглядим как получить доступ к элементам многомерного массива. В качестве примера возьмём выше описанные массивы служащих компании. Но перед сиим предлагаю накидать маленькую функцию, которая дозволит комфортно просматривать содержимое переменных в вашем коде. Я нередко использую её в работе:
Эта функция обычная обёртка для просмотра содержимого переменной с помощью print_r() либо var_dump() тегов <pre>. </pre> . Берите на вооружение.
И так, давайте узнаем имена и возраст всех служащих из первого двумерного массива:
В итоге выполнения этого кода, получим таковой перечень в html: 
Представьте что мы не знаем что содержится в переменной $multilevelArray3 , но нас требуют как-то представить структуру компании на страничке «О компании». Здесь нам понадобится функция print_p() описанная выше. Вызовем последующий код:
В итоге, на дисплее мы увидим такое сообщение: 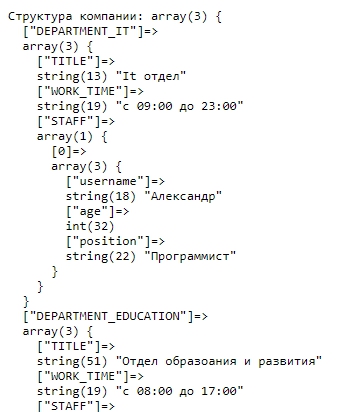
Мы лицезреем что в $multilevelArray3 хранится многоуровневый массив, на первом уровне которого находятся разделы компании с описанием, а снутри разделов по ключу STAFF доступен массив служащих этого отдела. Зная это мы можем написать последующий код, чтоб представить структуру компании:
Получим такую страничку: 
Таковым образом можно вывести к примеру страничку контактов веб-сайта, на которой должны быть «координаты» должностных лиц отвечающих за то либо другое направление деятельности компании. Оформление сами осознаете зависит от вашей фантазии и дизайна веб-сайта.
Обработка многомерного массива
Один из примеров обработки массива был представлен выше, когда мы просто вывели на экран содержимое многомерного массива в комфортном для юзера виде. Но это далековато не всё что можно созодать с массивами. К примеру мы можешь выполнить некоторый поиск по элементам выяснить сколько служащих старше 30 лет работает в нашей компании:
Тут мы применили функцию array_walk_recursive() которая обходит любой элемент массива вне зависимости от его вложенности и применяет к элементу пользовательскую функцию. В этом случае лямбда функция инспектирует что текущий элемент это возраст и что его значение больше 30 и увеличивает определённый во вне счётчик. Чтоб получить доступ в область видимости где применён счётчик употребляется система use и ссылка на переменную &$counter . В итоге вы увидите сообщение: Количество служащих старше 30 лет: 3.
Существует огромное количество примеров обработки массивов в PHP, но они выходят за рамки данной статьи.
SQL-Ex blog
Как применять функциональность массивов в SQL Server?
Обработка массива значений снутри процедуры либо функции является обыденным требованием в большинстве бизнес-кейсов. Так как SQL Server не поддерживает переменные типа массива, создатели употребляют перечень значений (основным образом, CSV) на входе.
Табличнозначные характеристики (TVP) заместо массивов
SQL Server 2008 ввел функциональность, именуемую табличнозначными параметрами (TVP). Она дозволяет юзерам соединять воединыжды значения в таблицу и обрабатывать их в табличном формате. Хранимые процедуры либо функции могут применять такую переменную в операторах соединения. Это дает возможность сделать лучше производительность и избежать поэлементных операций типа курсора.
- Табличные переменные не поддерживаются драйверами JDBC, Службы и приложения Java должны применять разбитые запятыми списки либо структурированные форматы типа XML для передачи перечня значений на сервер баз данных.
- Унаследованный код как и раньше работает и нужно должен поддерживаться, а процессы передвижения очень накладны для реализации.
Разбиение строчки в массив в SQL Server
Подход на базе таблицы чисел значит, что вы должны вручную сделать таблицу, содержащую довольно строк, чтоб самая длинноватая строчка, которую вы разбиваете, не превысила их число.
В данном примере я использую 100000 строк с кластеризованным индексом и сжатие на генерируемом столбце. Это дозволяет убыстрить поиск данных.
Замечу, что сжатие индекса может употребляться лишь в Enterprise версии SQL Server. В неприятном случае, не используйте эту опцию при разработке индекса.
Имея сделанную функцию NumbersTest, мы можем написать пользовательскую функцию, реализующую функциональность разбиения массива:
С иной стороны, если мы используем способ CTE, он не востребует таблицы чисел. Заместо нее будет употребляться рекурсивное CTE для извлечения каждой части строчки из «остатка» опосля предшествующей части.
Сейчас нам необходимо протестировать эти два подхода. Начнем с обычного теста для проверки корректности работы:
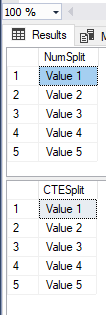
План выполнения показан ниже. Как видно, функции употребляют разные способы для заслуги 1-го и такого же результата.
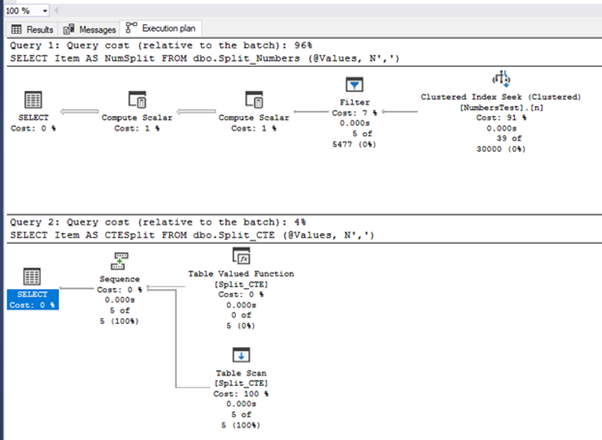
Так как набор данных очень невелик, производительность сопоставить нереально. Давайте проведем тестирование на большем наборе значений.
Поначалу нам необходимо сделать таблицу с тестовыми значениями. Я буду применять таблицу TestData, и наполню ее разными записями, делая их различных типов с зависимости от группы, к которой они должны быть приписаны:
Когда тестовые данные подготовлены, и функции готовы, мы можем испытать протестировать их на наборе данных большего размера, чтоб поглядеть производительность функций (для всякого типа данных, в секундах).
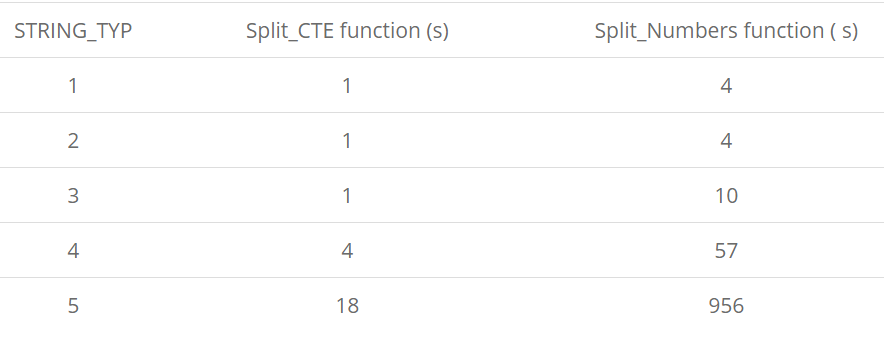
Как демонстрируют результаты, при увеличении строк преимущество способа CTE вырастает. Его следует предпочесть способу таблицы чисел.
Следует также принять во внимание, что результаты зависят от аппаратного обеспечения машинки на сервере.
Функции разбиения строк в MS SQL
В SQL Server 2016 возникла новенькая интегрированная функция STRING_SPLIT. Эта функция конвертирует строчку с разделителями в одностолбцовую таблицу, принимая два параметра: строчку для разбиения на значения и символ-разделитель. Она возвращает один столбец с именованием value.
План выполнения для этого запроса ниже:
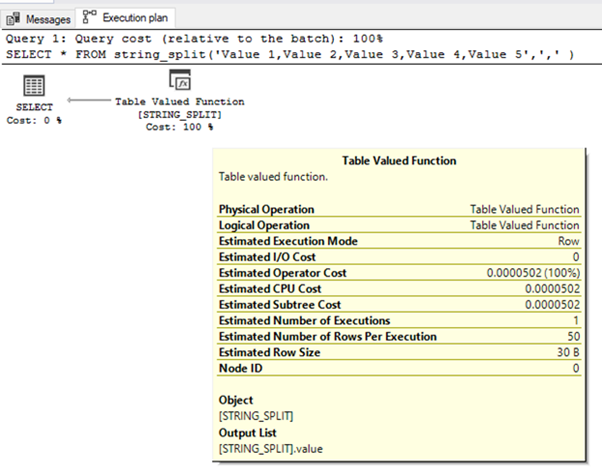
Значение Estimated Number of Rows Per Execution (предполагаемое число строк на выполнение) постоянно равно 50. Это не зависит от числа частей строчки.
Если у нас пользовательские табличнозначные функции, оценка числа строк равна 100.
Как табличнозначная функция, она может также употребляться в предложении FROM и выражениях WHERE, и всюду, где предполагается табличное выражение.
К примеру, будем применять базу данных AdventureWorks2019 для демонстрации внедрения string_split в операторе JOIN:
Если вы работаете с наиболее новейшей версией SQL Server, внедрение перечня значений с функцией STRING_SPLIT является хорошим. Это наилучшее и легкое в использовании решение без возможных багов неких решений третьих сторон.
- Принимается лишь односимвольный разделитель. Если для вас требуется больше знаков, придется применять пользовательскую функцию.
- Один выходной столбец — на выходе постоянно выходит одностолбцовая таблица без позиции элемента строчки в строке с разделителями. Это дозволяет сортировать лишь по имени элемента.
- Строковый тип данных — вы используете эту функцию для разделения строчки чисел (хотя все значения в выходном столбце являются числами, их типом данных является строчка). При соединении из с числовыми столбцами в остальных таблицах требуется выполнить преобразование типа данных. Если вы забудете выполнить очевидное преобразование, то сможете получить нежданные результаты.
Заключение
Современные способы обработки массивов разрешают верно решать требуемые задачки. В моей работе я постоянно предпочитаю встроенную функцию пользовательской, если они владеют схожей производительностью. Она постоянно доступна во всех базах данных.
Не считая того, значительно помогают в работе с SQL Server программные инструменты. Они быстрей предоставляют нужные значения и могут заавтоматизировать огромное количество задач, которые часто отымают у вас время, которое можно издержать с большей полезностью. К примеру, dbForge SQL Complete дает комфортную функцию получения значений агрегатов для избранных данных в сетке результатов SSMS (MIN, MAX, AVG, COUNT и т.д.).








